📝 Paper Summary
Hallucination suppression
White-box decoding strategies
HalluCana is a decoding strategy that uses lightweight classifiers over internal LLM hidden states to predict factuality before and during generation, vetoing hallucinatory paths without external retrieval.
Core Problem
Existing hallucination detection methods (e.g., SelfCheckGPT) require expensive assistive generations (sampling multiple times), leading to high latency and compute costs unsuitable for real-time applications.
Why it matters:
- Factuality hallucinations in long-form generation severely damage user trust in critical applications
- Current mitigation strategies are too computationally heavy (requiring 5-10x more tokens generated) for production use
- Reliable external knowledge sources for retrieval are not always available in low-resource domains
Concrete Example:
In generating 'King Charles was born in the Buckingham Palace', the model might confidently hallucinate 'Palace'. Existing methods need to sample 5 whole drafts to detect this inconsistency. HalluCana detects the uncertainty at the token 'born' using hidden states and corrects it immediately.
Key Novelty
Internal State Canary Lookahead
- Uses a lightweight classifier on the LLM's hidden states to predict if a future generation will be factual, acting as a 'canary' in the mine
- Introduces a 'veto' mechanism that prunes low-faithfulness branches entirely rather than just adjusting logits
- Applies lookahead selectively only at 'critical time steps' (high entropy points) to save compute and reduce noise
Architecture
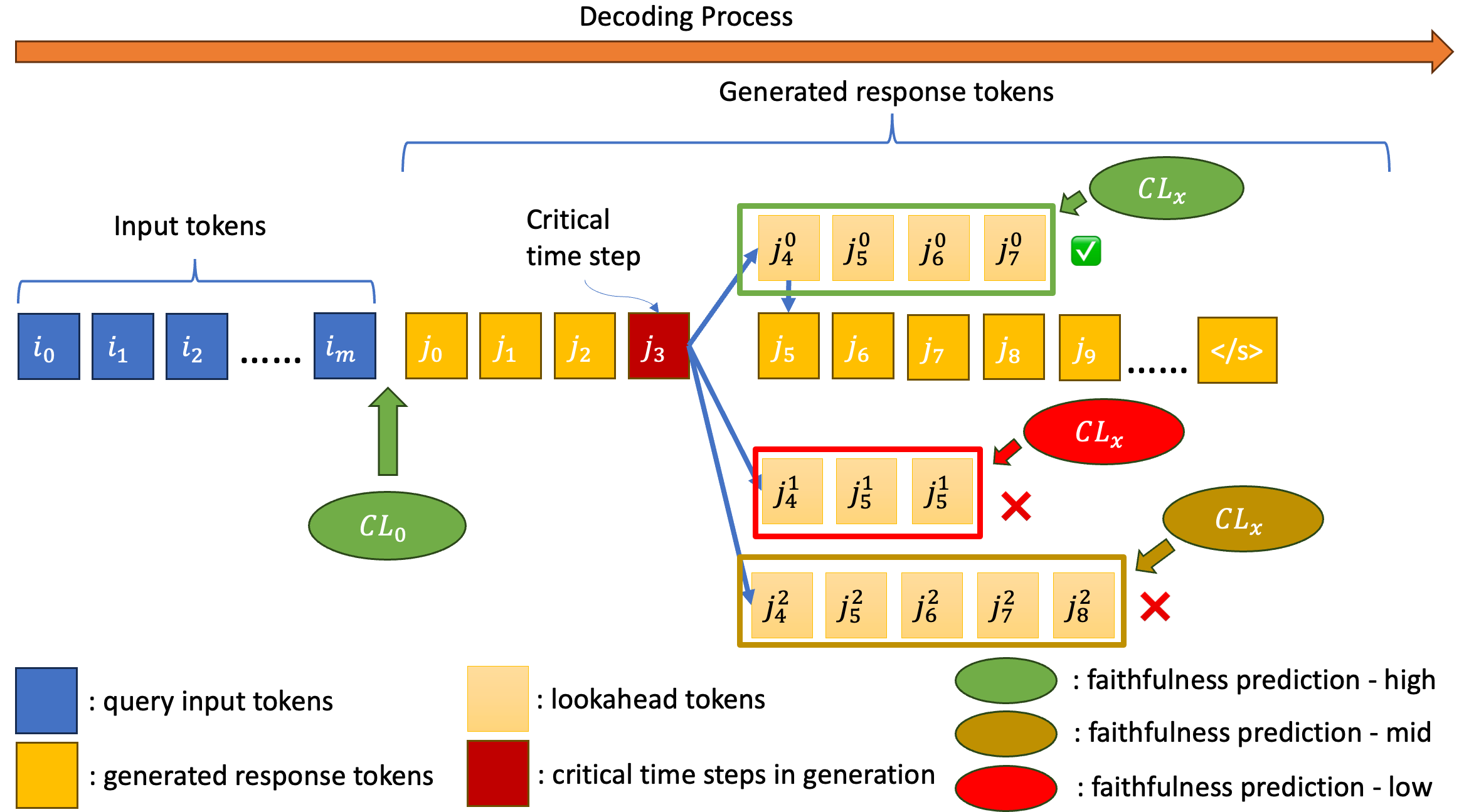
The decoding timeline of HalluCana showing Pre-hoc (CL0) and Ad-hoc (CLx) scoring phases.
Evaluation Highlights
- Improves generation quality (FACTSCORE) by up to 2.5x compared to standard greedy decoding on biography generation
- Outperforms SOTA baseline SelfCheckGPT while consuming over 6 times less compute
- Classifiers trained on 'context familiarity' (corpus frequency) perform comparably to those trained on ground-truth accuracy, proving internal factuality is grounded in pre-training data frequency
Breakthrough Assessment
8/10
Significant efficiency gain (6x less compute) over dominant sampling-based baselines while maintaining or beating performance. The finding that corpus familiarity effectively proxies for factuality training labels is scientifically insightful.