📝 Paper Summary
LLM Pretraining Dynamics
Knowledge Memorization and Generalization
Factual knowledge acquisition in LLMs occurs via small probability increases that accumulate but are diluted by power-law forgetting, which can be mitigated by larger batch sizes and data deduplication.
Core Problem
While LLMs are known to store factual knowledge, the specific mechanisms of how they acquire, maintain, and forget this knowledge during the pretraining process are poorly understood.
Why it matters:
- Understanding acquisition dynamics is crucial for explaining phenomena like the failure to learn long-tail knowledge
- Clarifies the benefits of dataset deduplication and scaling laws beyond just loss metrics
- Provides insights into how training conditions (batch size, model size) affect knowledge retention
Concrete Example:
When a model encounters a fact like 'X is the CEO of Y' during pretraining, does it learn it immediately? If it sees it again later, does it remember? Current understanding doesn't explain why models fail to learn rare facts despite seeing them, or why deduplication helps.
Key Novelty
Step-wise Analysis of Factual Knowledge Injection
- Injects unseen 'Fictional Knowledge' into intermediate pretraining checkpoints and tracks the exact log-probability trajectory of specific facts step-by-step
- Defines 'Local Acquisition Maxima' to measure immediate learning and 'Retainability' to measure long-term forgetting
- Identifies a power-law relationship between training steps and the forgetting of acquired knowledge
Architecture
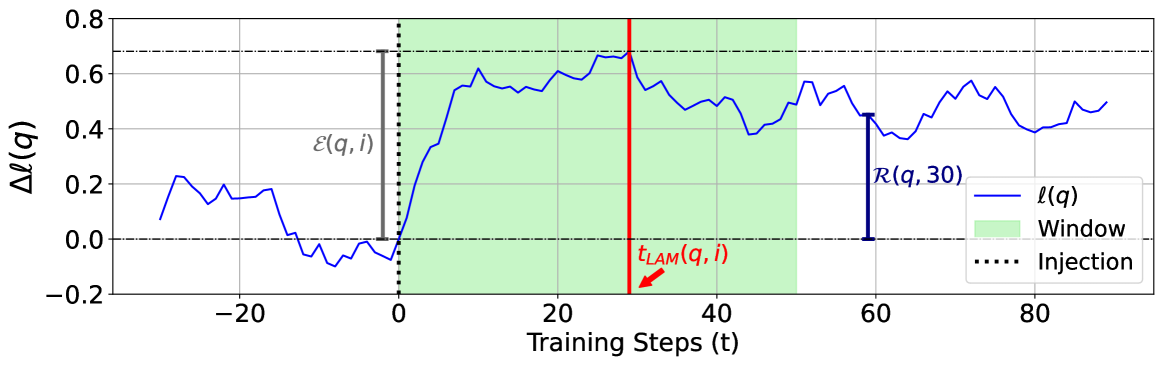
Conceptual diagram of the metric definitions (Local Acquisition Maxima, Effectivity, Retainability) based on log probability trajectories.
Evaluation Highlights
- Forgetting follows a power-law curve: LLMs lose acquired knowledge probability improvements at a predictable rate relative to training steps
- Larger batch sizes (2048 vs 128) significantly enhance robustness to forgetting, allowing knowledge to be retained longer
- Deduplicated training data leads to slower forgetting compared to duplicated data, explaining the empirical benefit of deduplication
Breakthrough Assessment
7/10
Provides a strong empirical framework and theoretical intuition (power-law forgetting) for pretraining dynamics, offering plausible explanations for known phenomena like long-tail forgetting and deduplication benefits.
