📝 Paper Summary
Hallucination suppression
Contrastive Decoding
PruneCD improves large language model factuality by using a layer-pruned version of the model itself as an amateur for contrastive decoding, yielding more informative contrasts than early exit methods.
Core Problem
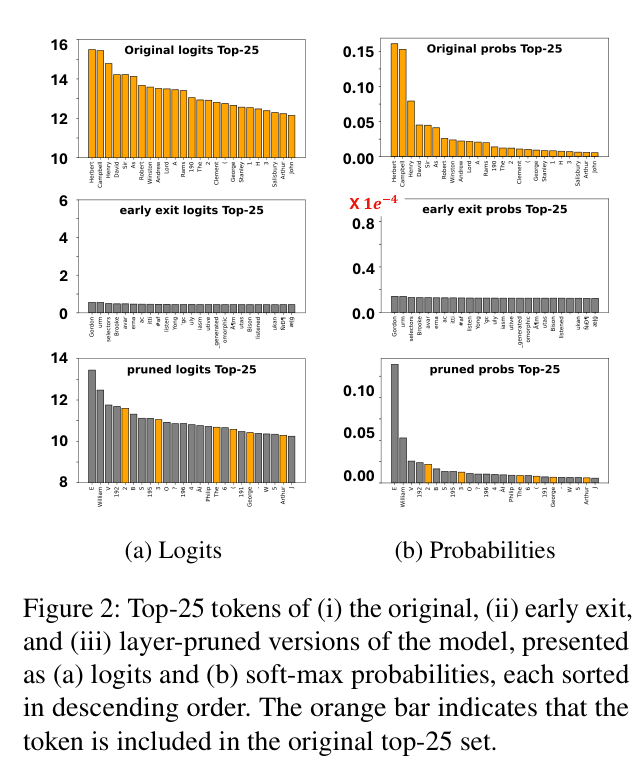
Existing contrastive decoding methods like DoLa use 'early exit' logits as a negative reference, but these logits are often flat, low-magnitude, and uninformative, failing to provide a meaningful contrast for correcting hallucinations.
Why it matters:
- Hallucinations in LLMs generate fluent but factually incorrect outputs, especially for underrepresented knowledge
- Current single-model contrastive methods (like DoLa) often select the earliest possible exit layer, resulting in weak signals that cannot effectively suppress incorrect tokens
- Deploying separate amateur models for contrastive decoding is computationally expensive; single-model solutions are preferred but need to be effective
Concrete Example:
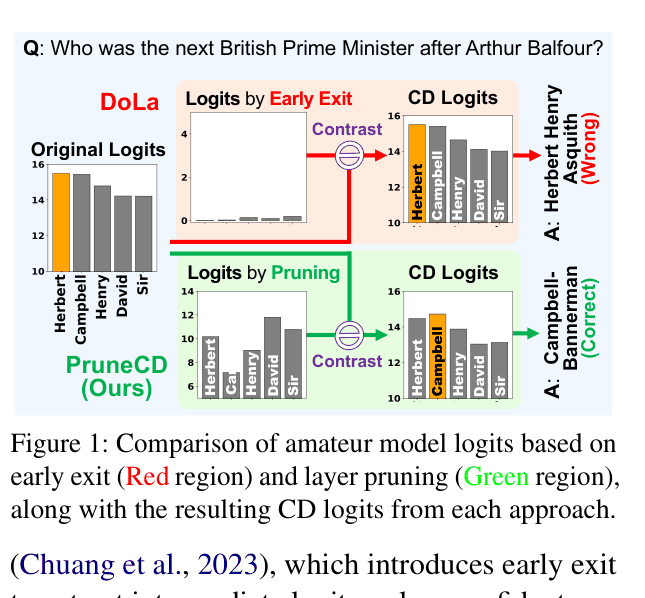
When asked 'Who was the next British Prime Minister after Arthur Balfour?', the expert model might hallucinate 'Herbert Henry Asquith'. DoLa's early exit logits are flat (near-uniform distribution) and offer no strong signal to correct this. PruneCD's pruned model retains structure but is less confident, allowing the contrast to successfully amplify the correct answer 'Campbell-Bannerman'.
Key Novelty
PruneCD (Contrastive Decoding via Layer Pruning)
- Constructs the 'amateur' model by skipping specific intermediate layers (pruning) rather than exiting early, preserving the final sharpening layers while degrading factual content
- Identifies optimal pruning layers via an efficient ablation search that maximizes the drop in truthfulness on a validation set
- Implements contrastive decoding in a single forward pass using batched inference (batch 0 = full model, batch 1 = pruned model) to minimize latency
Architecture
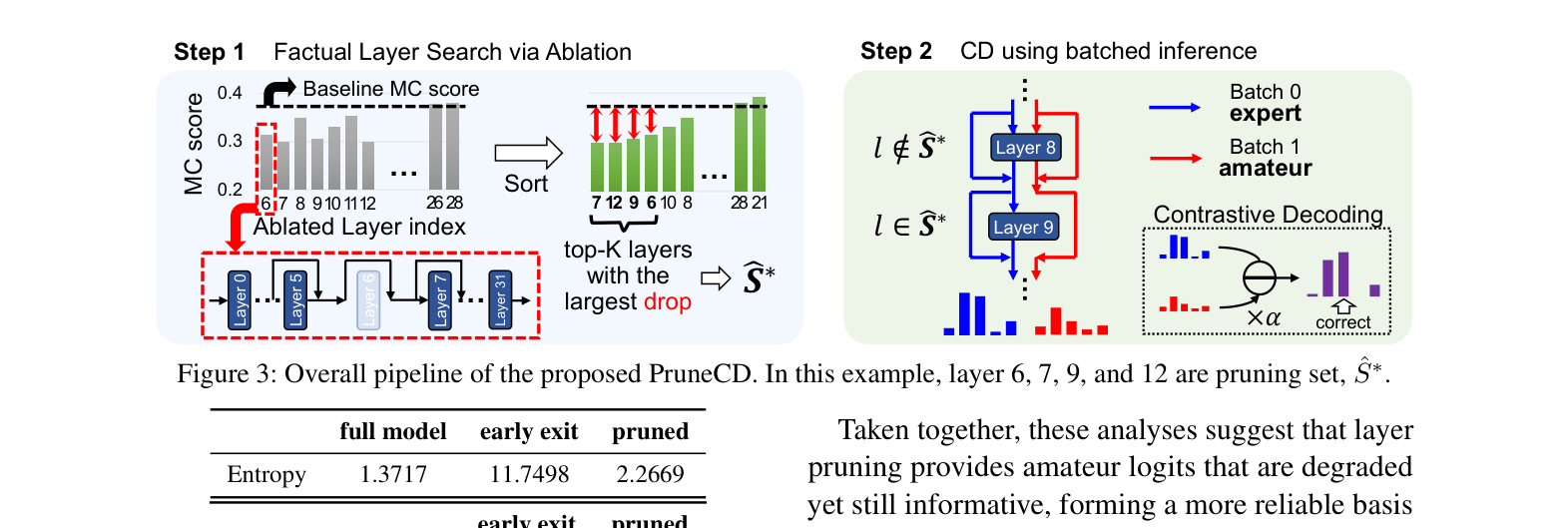
The overall pipeline of PruneCD, illustrating the offline layer search and the runtime batched inference mechanism.
Evaluation Highlights
- +13.67% improvement in Truthfulness (TruthfulQA Gen) over DoLa on Llama-3.1-8B-Instruct (92.78% vs 79.11%)
- Achieves superior performance on TruthfulQA, TriviaQA, and Natural Questions across multiple model sizes (1B, 3B, 8B) compared to DoLa, Activation Decoding, and END
- Maintains inference speed comparable to greedy decoding (33.7 tokens/s vs 35.8 tokens/s) due to efficient batched implementation
Breakthrough Assessment
8/10
Significantly outperforms strong baselines like DoLa and END with a simpler, more intuitive mechanism (pruning vs early exit) while remaining computationally efficient. A practical drop-in replacement for existing decoding strategies.