📝 Paper Summary
Factuality Decoding
Hallucination Suppression
SLED improves LLM factuality by treating inference as an optimization process where final-layer logits are updated to align with latent knowledge extracted from early-layer contrasts.
Core Problem
LLMs often hallucinate because their final output distribution (logits) deviates from real-world facts, even when the model possesses the correct latent knowledge in its internal representations.
Why it matters:
- Hallucinations undermine trust in LLMs for practical applications where factual accuracy is non-negotiable.
- Existing solutions like Retrieval-Augmented Generation (RAG) require external databases, which can be costly or unavailable.
- Prior decoding methods (like DoLa) struggle with selecting the optimal premature layer for contrast, leading to inconsistent performance.
Concrete Example:
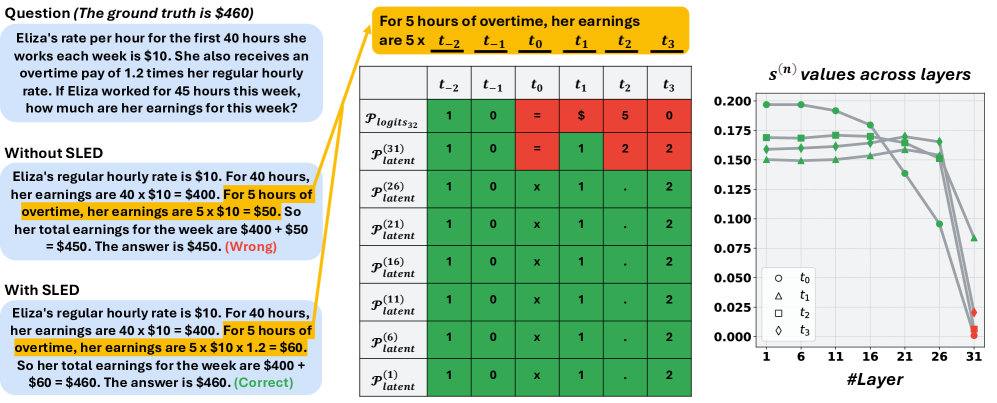
When an LLM is asked a factual question, its internal layers might encode the correct entity (e.g., 'Paris'), but the final layer's softmax distribution might assign a higher probability to an incorrect entity (e.g., 'London') due to superficial correlations. Standard decoding picks 'London', ignoring the internal evidence for 'Paris'.
Key Novelty
Self Logits Evolution Decoding (SLED)
- Interprets the training process as 'logits evolution' towards truth and replicates this at inference time by treating the final logits as a variable to be optimized.
- Estimates the 'true' distribution by contrasting final-layer logits with *all* early-layer logits, using the direction of this difference to approximate the gradient towards factual truth.
- Updates the final logits using a single-step gradient descent approach based on this estimated factual distribution, balancing the original output with internal latent knowledge.
Architecture
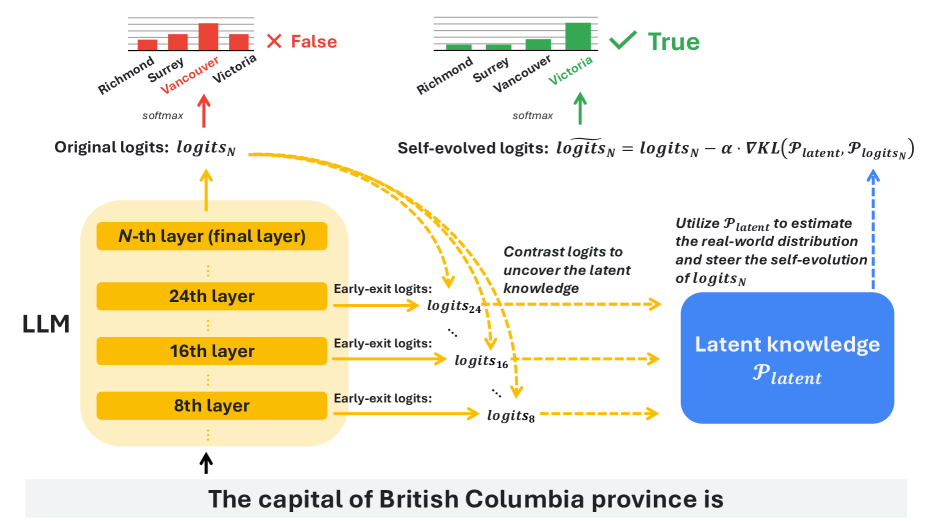
The workflow of SLED. It depicts the process of extracting logits from early and final layers, estimating the latent factual distribution, and updating the final logits.
Evaluation Highlights
- Consistent improvements in factual accuracy across diverse model families (Gemma, Qwen, Mixtral, GPT-OSS) and scales (1B to 45B).
- Achieves state-of-the-art performance among layer-wise contrastive decoding methods on benchmarks like TruthfulQA and multiple-choice tasks.
- Maintains natural language fluency and introduces negligible latency overhead compared to complex search-based methods.
Breakthrough Assessment
7/10
Offers a mathematically grounded perspective (logits evolution) on contrastive decoding that unifies previous heuristic approaches (like DoLa) and eliminates the need for manual layer selection.