📝 Paper Summary
Hallucination suppression
Inference-time intervention
DoLa improves LLM factuality by contrasting output logits from mature later layers against premature earlier layers, amplifying factual knowledge that emerges only in the final stages of processing.
Core Problem
LLMs frequently hallucinate content inconsistent with pretraining facts because the maximum likelihood objective encourages mass-seeking behavior, relying on superficial linguistic patterns from earlier layers rather than factual knowledge.
Why it matters:
- Deployment in high-stakes fields (clinical, legal) is bottlenecked by the generation of untrustworthy text
- Existing solutions often require expensive retrieval (RAG) or additional fine-tuning (RLHF), which adds complexity and training cost
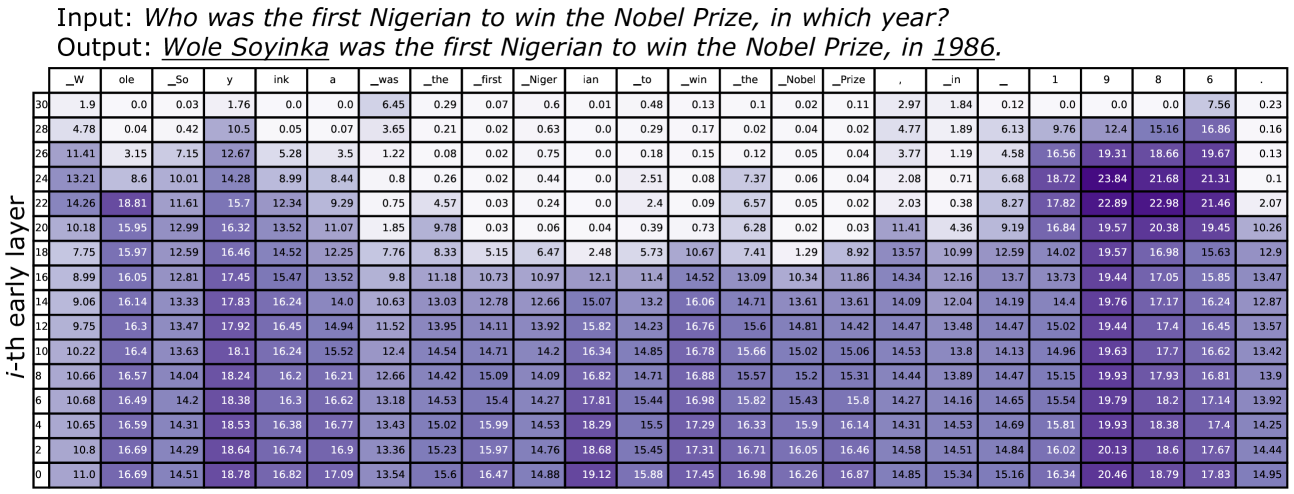
- Linguistic patterns (syntax) often dominate generation probability even when the factual content is incorrect
Concrete Example:
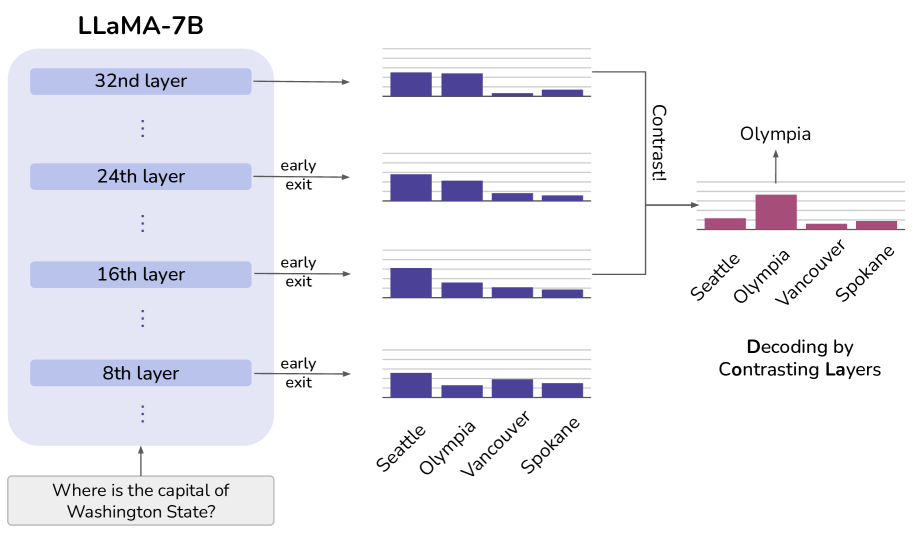
When asking 'The capital of Washington is...', the token 'Seattle' maintains high probability across all layers due to syntactic plausibility. The correct answer 'Olympia' only sees a probability spike in the final layers. Standard decoding might pick 'Seattle' or mix them up, whereas contrasting the layers reveals 'Olympia' as the factual choice.
Key Novelty
Decoding by Contrasting Layers (DoLa)
- Leverages the observation that lower transformer layers encode linguistic/syntactic information, while factual knowledge tends to localize in higher layers
- Dynamically selects a 'premature' layer based on Jensen-Shannon Divergence and subtracts its log-probabilities from the final 'mature' layer to cancel out non-factual linguistic noise
- Requires no external retrieval, no model fine-tuning, and only adds a small latency overhead during decoding
Architecture
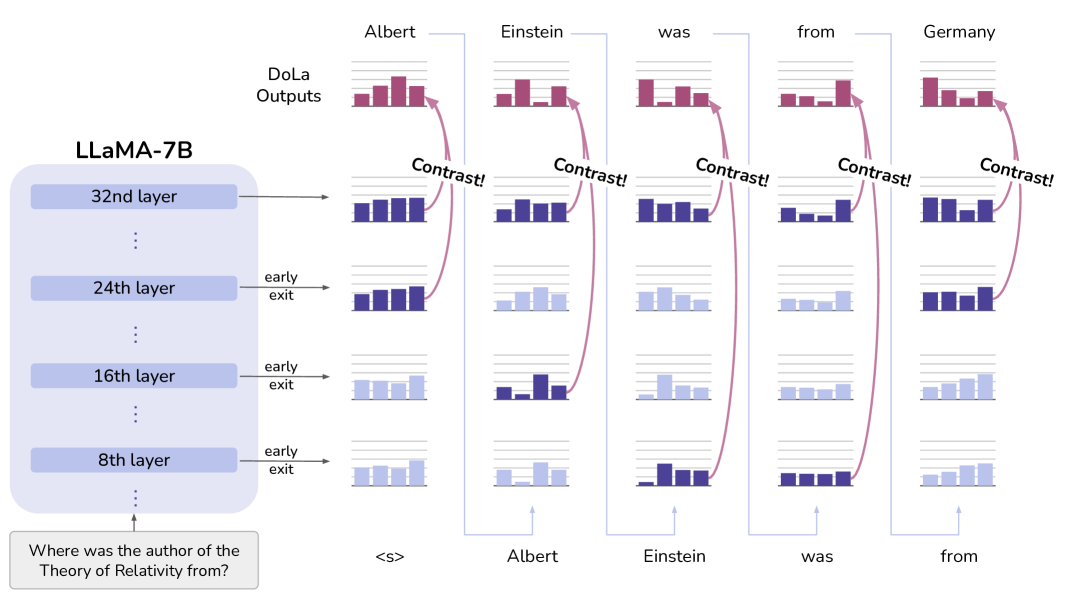
Overview of the DoLa decoding process during inference.
Evaluation Highlights
- Improves TruthfulQA scores by 12-17% absolute points across LLaMA family models (7B to 65B), matching methods that use supervised fine-tuning (ITI)
- Outperforms Contrastive Decoding (CD) on multiple choice and open-ended generation, improving 'Truth*Info' scores significantly without the high refusal rate seen in CD
- Demonstrates consistent gains on reasoning tasks (StrategyQA, GSM8K), boosting accuracy by 1-4% while baselines like CD often degrade performance
Breakthrough Assessment
8/10
Simple, effective, and parameter-free method that significantly reduces hallucinations. It offers a practical inference-only solution to a major LLM problem without requiring retraining or external modules.