📝 Paper Summary
Hallucination suppression
Contrastive Decoding
DHI mitigates hallucinations by training an 'Evil Model' to generate diverse errors via a reversed loss on correct tokens, then using its output to penalize low-confidence predictions from a base model.
Core Problem
Existing methods like ICD (Induce-then-Contrast Decoding) train 'Evil' models on narrow, pre-defined hallucination types, limiting their ability to catch diverse errors and requiring expensive annotated datasets.
Why it matters:
- Models trained on specific error patterns struggle to generalize to unseen hallucination types.
- Inducing hallucinations at specific positions can disrupt the coherence of subsequent token generation, degrading overall text quality.
- Dependence on curated hallucination datasets limits scalability and applicability to new domains.
Concrete Example:
If a user asks 'Who won the 2020 election?', a standard 'Evil' model trained only to swap names might say 'Trump', but miss other error types like fabricating a date. DHI's Evil Model is discouraged from saying 'Biden' entirely, forcing it to explore various wrong paths (names, dates, entities), providing a richer signal for correction.
Key Novelty
Diverse Hallucination Induction (DHI)
- Instead of teaching the Evil Model specific wrong answers, DHI penalizes the *correct* answer in the loss function, forcing the model to generate *anything but* the truth.
- Modifies the attention mask during Evil Model training so that the artificially induced errors don't confuse the model when generating subsequent tokens, preserving fluency.
- Applies contrastive penalties only when the base (Positive) model is uncertain, preventing the degradation of high-confidence correct facts.
Architecture
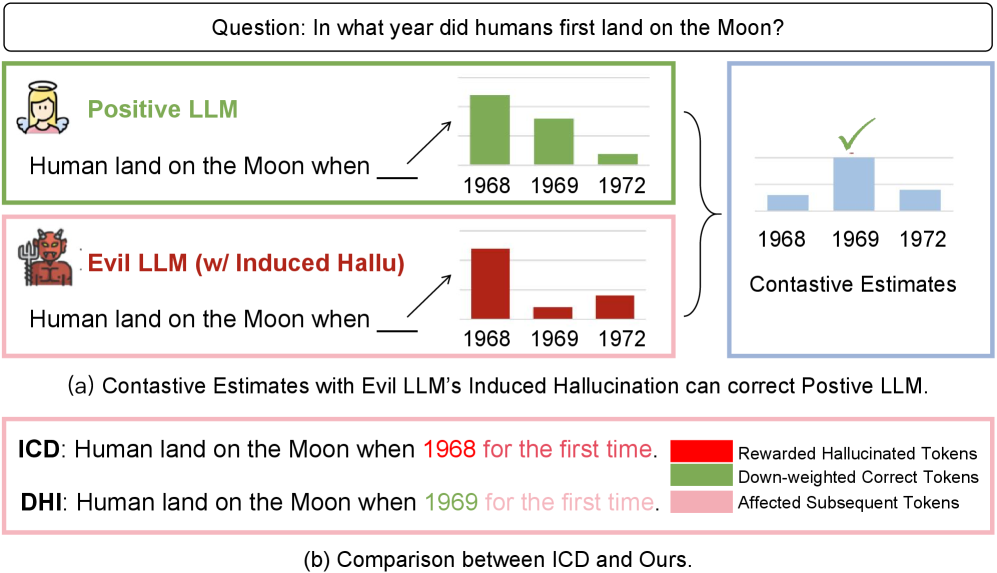
Conceptual comparison of standard hallucination induction (ICD) vs. Diverse Hallucination Induction (DHI).
Evaluation Highlights
- Achieves highest average score of 53.2 on TruthfulQA, outperforming ICD (50.5) and CD (42.2).
- +3.7 point improvement on TruthfulQA MC3 (complex reasoning) compared to the strongest baseline (ICD).
- Achieves 68.1 Factual Precision Score on FactScore (biography generation), surpassing ICD by 1.8 points.
Breakthrough Assessment
7/10
Offers a clever inversion of the training objective (penalizing truth rather than rewarding specific lies) to improve generalization. Strong empirical results, though primarily an evolution of the existing ICD framework.