📝 Paper Summary
Agentic RAG pipeline
RL-based
O2-Searcher is a reinforcement learning-based agent that decouples reasoning from knowledge by interacting with a local search environment, optimizing for both open-ended exploration and closed-ended accuracy.
Core Problem
LLMs rely on static parametric knowledge that quickly becomes obsolete and lack the ability to effectively handle open-ended questions which require extensive, multi-turn exploration and non-unique answers.
Why it matters:
- Current search agents primarily address closed-ended problems with clear objectives, neglecting open-ended tasks that require comprehensive, multi-aspect responses.
- Relying on static model weights leads to hallucinations and factual inaccuracies when dealing with dynamic, real-time, or specialized information.
- Using live web search for training is slow and costly, hindering the large-scale reinforcement learning needed to teach agents complex search behaviors.
Concrete Example:
For an open-ended question like 'What are the impacts of the metaverse on education?', a standard model might give a generic, outdated summary. O2-Searcher actively queries 'metaverse applications in education', 'virtual classrooms pros cons', and 'future trends', synthesizing diverse findings into a structured report.
Key Novelty
RL-based Search Agent with Dual-Mode Optimization (O2-Searcher)
- Decouples internal reasoning from external knowledge by training the agent to master search interaction skills (finding, understanding, applying) rather than memorizing facts.
- Uses a unified training mechanism with distinct reward functions for closed-ended (accuracy) and open-ended (diversity, format, factuality) questions to handle both types flexibly.
- Introduces a locally simulated search environment that caches web pages and Wikipedia, enabling rapid, low-cost reinforcement learning interactions compared to live API calls.
Architecture
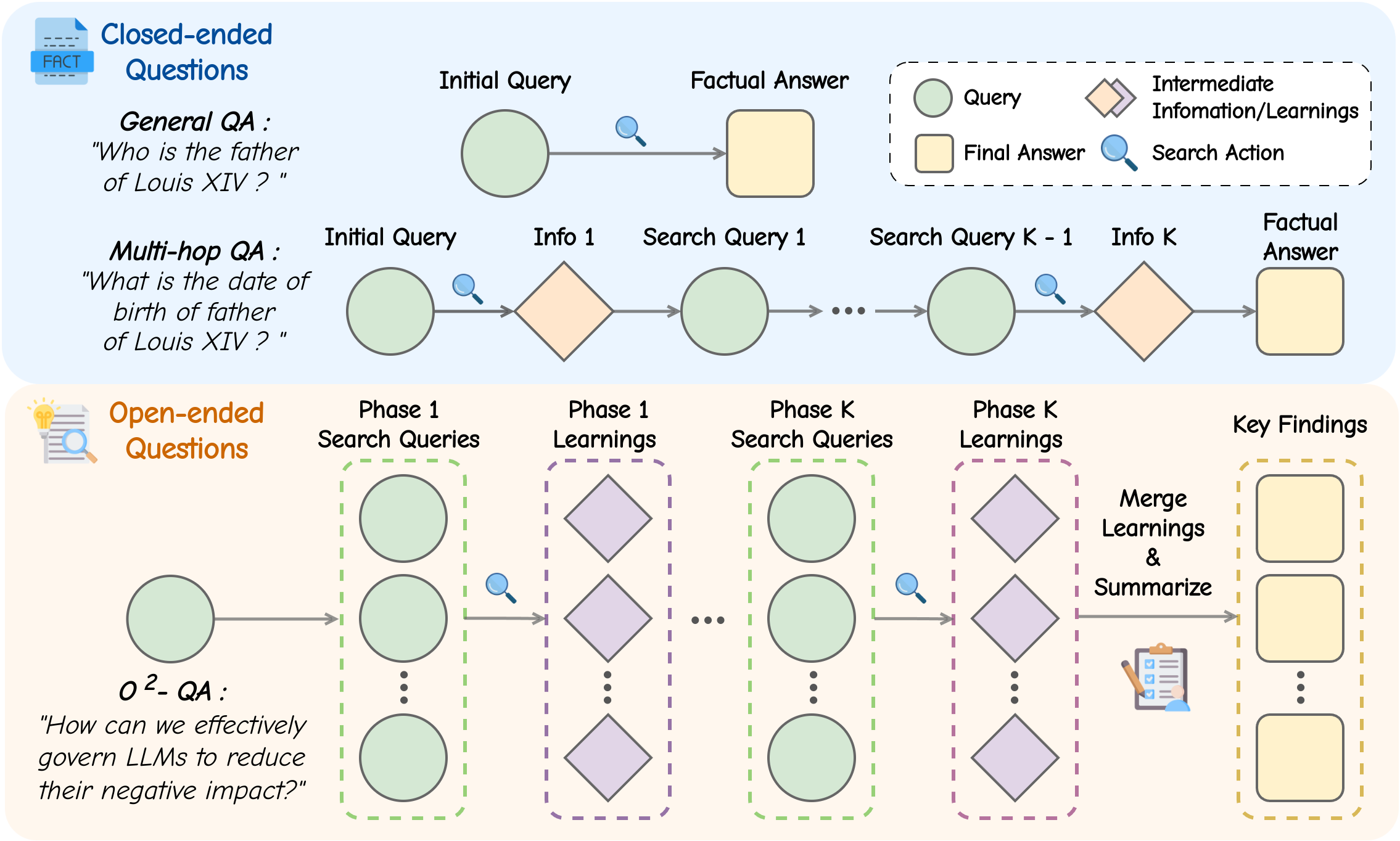
The inference workflow of O2-Searcher involving iterative thought, search action generation, local retrieval, and answer synthesis.
Evaluation Highlights
- Significantly outperforms SOTA agents (Search-R1, Perplexity-Pro) on the newly constructed O2-QA benchmark for open-ended questions using only a 3B model.
- Achieves SOTA results on closed-ended benchmarks (NQ, HotpotQA) among similarly-sized models, matching performance of larger 7B models.
- Demonstrates effective generalization by maintaining high performance on both deterministic fact-seeking and exploratory open-ended tasks.
Breakthrough Assessment
8/10
Strong contribution in addressing the underexplored area of open-ended search agents via RL. The efficient local environment and specialized reward design for open-endedness are significant practical advancements.