📝 Paper Summary
LLM-as-a-Judge
Factual Inconsistency Detection
Text Summarization Evaluation
ChatGPT outperforms existing metrics in evaluating factual consistency of text summaries in a zero-shot setting, though it exhibits biases toward lexical overlap and struggles with reasoning.
Core Problem
Existing methods for evaluating factual consistency in summarization (like NLI or QA-based metrics) are computationally expensive, rely on annotated data, or correlate poorly with human judgments.
Why it matters:
- Pre-trained language models often generate summaries with 'hallucinations'—content not supported by the source document—undermining trust in automated summarization.
- Current state-of-the-art evaluation metrics (like FactCC, SummaC) require training on large datasets or complex pipelines, yet still show limited agreement with human annotators.
Concrete Example:
In a CoGenSumm example, a summary claims 'half of' a group was affected, while the article implies the whole group. Traditional metrics and ChatGPT (in simple mode) fail to catch this due to high lexical overlap, but ChatGPT correctly identifies the error when forced to rank it against a correct summary.
Key Novelty
Zero-Shot Factual Inconsistency Evaluator using ChatGPT
- Reframe factual evaluation as three distinct tasks for an LLM: binary entailment (yes/no), summary ranking (A vs B), and scalar rating (1-10), without any model fine-tuning.
- Employ Zero-Shot Chain-of-Thought (CoT) prompting to trigger reasoning capabilities, asking the model to 'think step by step' before delivering a consistency verdict.
Architecture
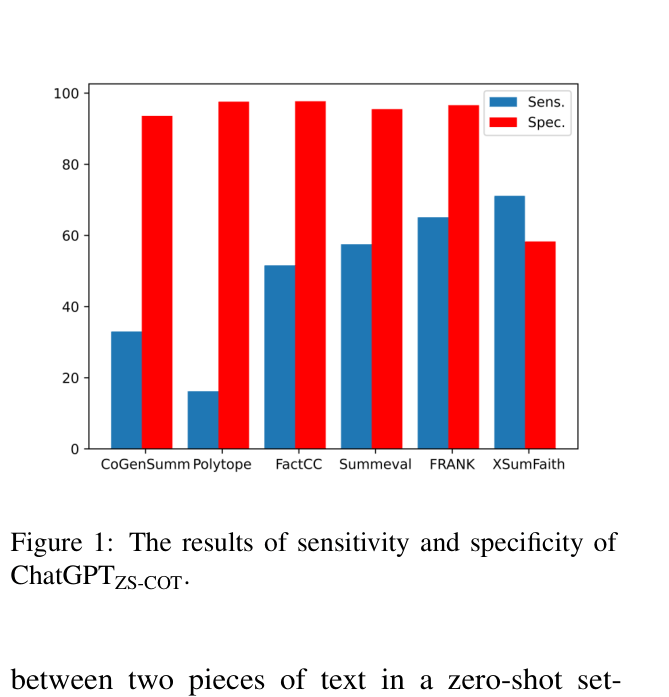
A bar chart breaking down the Balanced Accuracy of ChatGPT ZS-COT into Sensitivity (Recall of True Positives) and Specificity (Recall of True Negatives) across six datasets.
Evaluation Highlights
- Outperforms SummaC ZS by +3.9% accuracy on CoGenSumm and +1.6% on SummEval in binary entailment tasks using Chain-of-Thought prompting.
- Achieves 85.2% accuracy in Summary Ranking, surpassing both supervised baselines like FactCC (70.0%) and human performance (83.9%) on the tested dataset.
- Dominates Pearson correlation with human judgments on the FRANK dataset (0.70 vs next best 0.20) for consistency rating.
Breakthrough Assessment
7/10
Strong empirical evidence that off-the-shelf LLMs outperform specialized fine-tuned metrics for factuality. However, the study identifies critical flaws (reasoning errors, lexical bias) preventing full reliance.