📝 Paper Summary
Long-term conversational memory evaluation
Cognitive memory in LLM agents
LoCoMo-Plus is a benchmark and evaluation framework that tests whether LLMs can retain implicit user constraints (goals, values) across long dialogues without explicit factual cues or task hints.
Core Problem
Existing benchmarks equate conversational memory with explicit factual recall, failing to test if models can adhere to implicit constraints (goals, values) when surface-level semantic retrieval fails.
Why it matters:
- Realistic interactions rely on inferred constraints (e.g., 'I'm studying') rather than just fact retrieval, which current benchmarks miss
- Current evaluation protocols using task-disclosed prompting bias results by signaling models to switch to 'memory mode' rather than naturally recalling context
- String-matching metrics (BLEU, ROUGE) are misaligned with cognitive memory, where multiple diverse responses can be valid if they satisfy the implicit constraint
Concrete Example:
A user mentions preparing for an exam (implicit constraint: avoid distractions). Much later, they ask 'Should I watch this new TV series?' A factual memory system might just answer the question directly. A cognitive memory system should recognize the conflict with the earlier goal and advise against it, even though the query has no keywords overlapping with 'exam'.
Key Novelty
Constraint-Consistency Evaluation for Cognitive Memory
- Constructs 'cue-trigger' pairs with semantic disconnect: the trigger query (e.g., about TV) has no lexical overlap with the memory cue (e.g., about exams), forcing implicit constraint application
- Replaces string-matching metrics with a 'constraint consistency' check, defining correctness as staying within a valid behavioral boundary rather than matching a reference answer
- Removes 'task disclosure' from prompts during evaluation to prevent models from artificially adapting their generation style based on knowing they are being tested on memory
Architecture
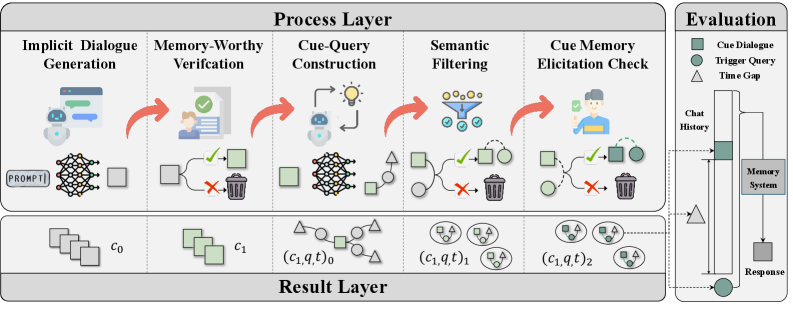
The LoCoMo-Plus data construction pipeline, showing how cues and triggers are generated and filtered.
Evaluation Highlights
- Cognitive memory performance collapses compared to factual memory across all models; even strong models show severe degradation when implicit constraints are required
- Explicit task disclosure (telling the model 'this is a memory task') artificially inflates scores on temporal and adversarial tasks by altering generation strategy
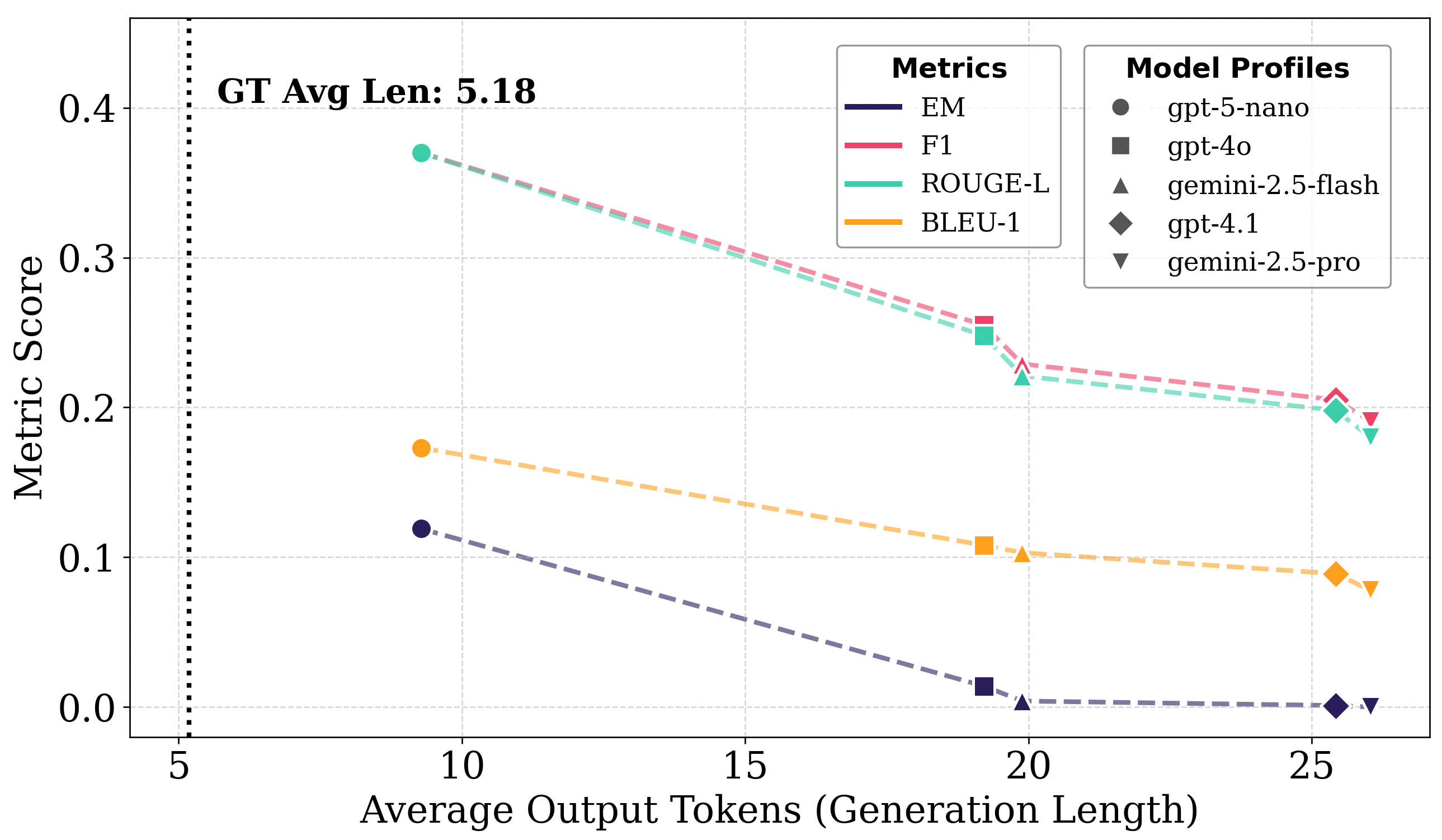
- Generation-based metrics (BLEU, ROUGE) show systematic length bias, penalizing valid answers that differ in verbosity from the reference, while the proposed constraint-based judge remains stable
Breakthrough Assessment
8/10
Identifies a fundamental flaw in current memory benchmarks (focus on explicit retrieval vs. implicit constraints) and proposes a rigorous correction. The shift from factual recall to behavioral consistency is a significant conceptual advance.