📝 Paper Summary
Hallucination suppression
Decoding strategies
DeLTa improves LLM factuality and reasoning by treating layer-wise logits as a time series and using linear regression to predict an extrapolated 'virtual layer' distribution where correct tokens are more probable.
Core Problem
LLMs frequently generate hallucinations and logical errors because standard decoding relies on the final layer's logits, which may not fully capture the model's internal confidence evolution.
Why it matters:
- Hallucinations pose severe risks in high-stakes fields like medicine and law where factual accuracy is paramount
- Existing mitigation methods (dataset selection, loss modification) require expensive retraining or additional data
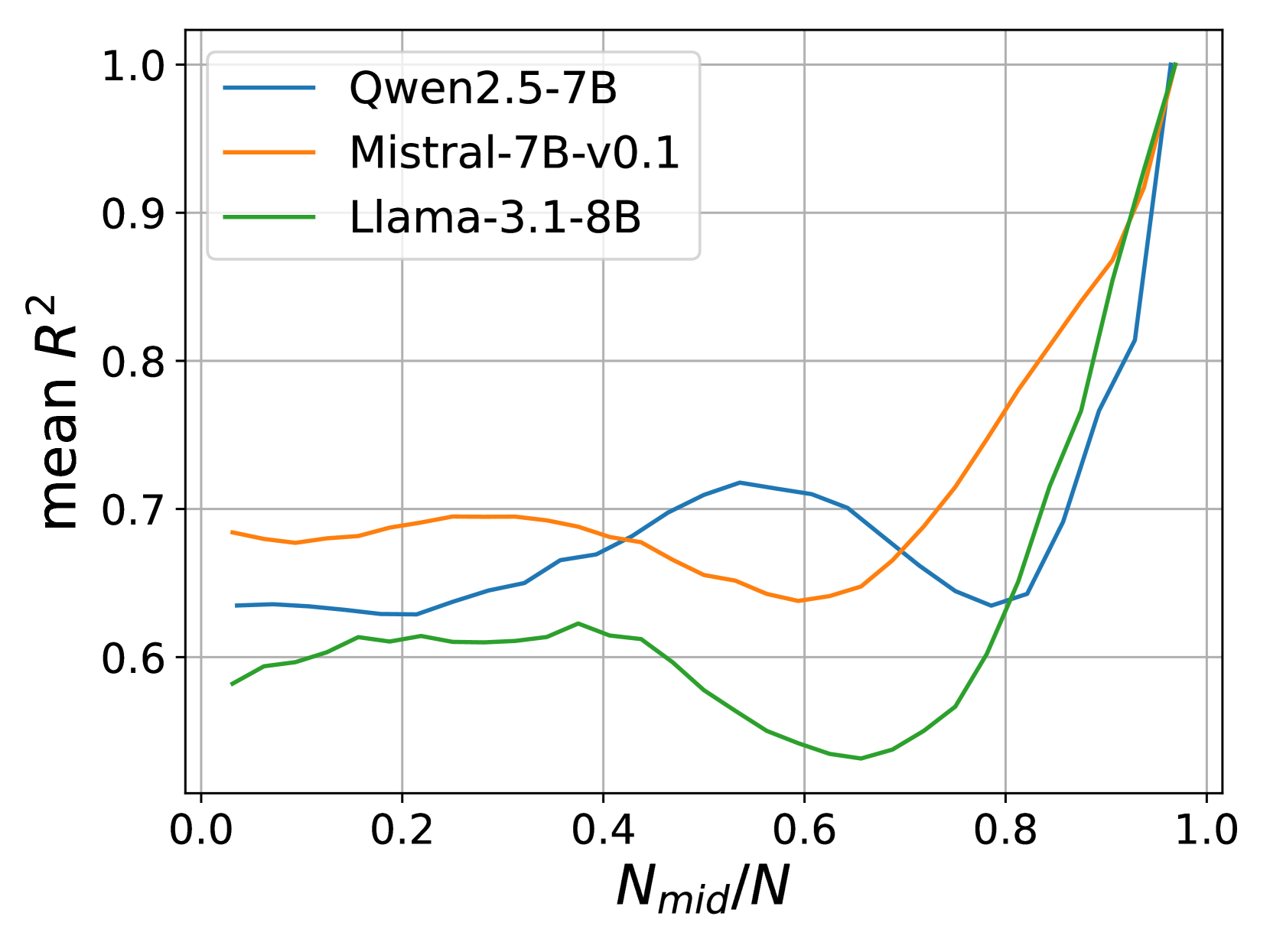
- Current inference-time methods like DoLa rely on fixed layer buckets or simple differencing, potentially missing the continuous trend of information refinement across layers
Concrete Example:
When answering a factual question, an LLM might assign high probability to a plausible but incorrect entity in early layers. While the probability of the correct entity rises in later layers, standard decoding might still pick the wrong one if the final layer isn't decisive enough. DeLTa extrapolates this rising trend to a virtual layer where the correct token dominates.
Key Novelty
Decoding by Logit Trajectory (DeLTa)
- Treats the sequence of logits from intermediate layers to the final layer as a time-series trajectory
- Applies linear regression to this trajectory to predict logits at a hypothetical 'virtual layer' beyond the model's actual depth
- Leverages the observation that correct token probabilities tend to increase linearly across higher layers, amplifying this signal for better selection
Architecture
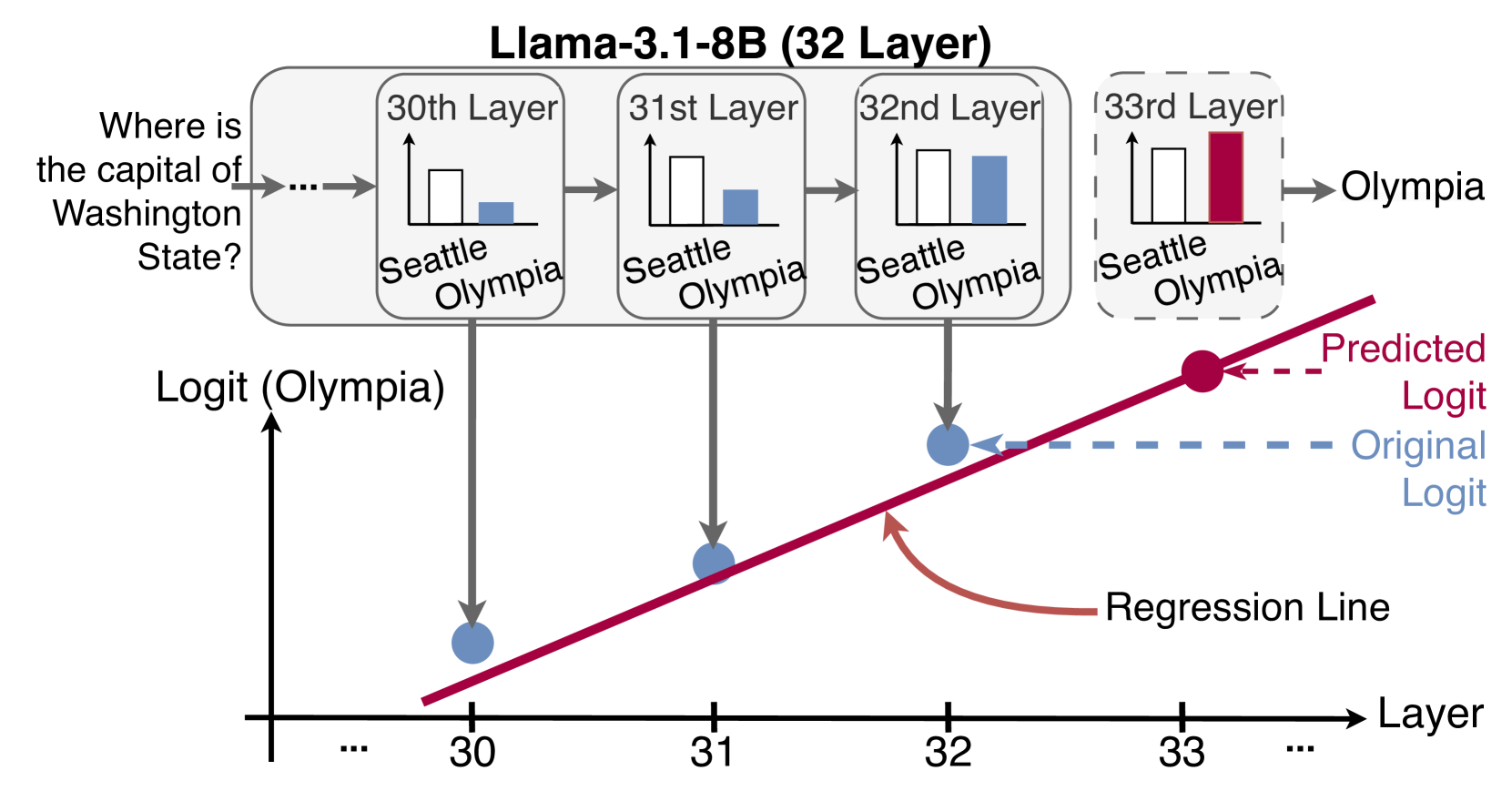
Conceptual diagram of DeLTa. It illustrates how logits for a correct token (e.g., 'Paris') increase across layers while incorrect ones fluctuate or decrease. DeLTa fits a line to these logits and extrapolates to a virtual layer to select the correct token.
Evaluation Highlights
- +4.9% improvement on TruthfulQA (%True*Info) using Llama-3.1-8B compared to raw model output
- +8.1% accuracy gain on StrategyQA using Llama-3.1-8B, enhancing reasoning capabilities without retraining
- +7.3% accuracy improvement on GSM8K using Llama-3.1-8B, demonstrating gains in chain-of-thought reasoning
Breakthrough Assessment
7/10
Offers a computationally lightweight, training-free method that consistently improves both factuality and reasoning across multiple models. It refines the intuition of prior work (DoLa) into a more general regression framework.