📝 Paper Summary
Hallucination suppression
Factuality alignment
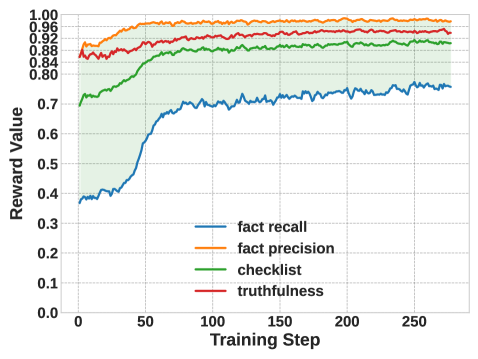
KLCF reduces hallucinations by aligning a model's generated text with its own pre-existing internal knowledge using a dual-reward system that penalizes fabrication and rewards recall of verified facts.
Core Problem
Existing RLHF methods rely on preference rewards that ignore the model's internal knowledge boundaries, encouraging models to fabricate facts they don't actually know to satisfy user queries (the 'hallucination tax').
Why it matters:
- Standard RLHF often pushes models to generate plausible-sounding but factually incorrect content when the model lacks the underlying knowledge
- Current factuality solutions like FActScore rely on slow external retrieval during training, making them computationally expensive and hard to scale for online RL
- Existing methods often focus only on precision (avoiding errors), leading to overly conservative models that refuse to answer even when they possess the knowledge
Concrete Example:
When asked a complex long-form question, a standard RLHF model might invent specific dates or names to make the answer look complete. In contrast, KLCF restricts the model to only output facts it has previously verified it 'knows' (via a pre-computed checklist) and is confident about, reducing fabrication.
Key Novelty
Knowledge-Level Consistency Reinforcement Learning Framework (KLCF)
- Dual-Fact Alignment: Simultaneously optimizes for 'Recall' (mentioning facts the model definitely knows) and 'Precision' (avoiding facts the model is unsure about)
- Offline-to-Online Bridge: Instead of retrieving external data during RL training (which is slow), KLCF pre-computes a 'Checklist' of what the model knows and trains a distinct Truthfulness Reward model offline, making the online RL step purely internal and fast
Architecture
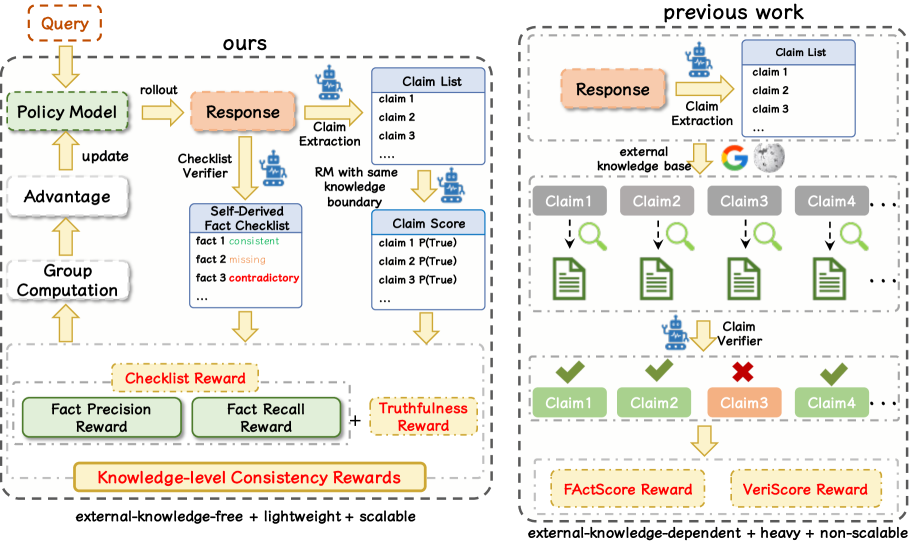
Comparison between KLCF (Left) and Previous Methods (Right). It illustrates the Offline Data Preparation phase feeding into the Online RL phase.
Evaluation Highlights
- +3.4 to +10.0 improvement in F1 score on LongFact-Obj benchmark compared to RLHF baseline
- Reduces hallucination rate by ~4-8 percentage points on LongFact-Obj compared to RLHF
- Achieves comparable or better performance than retrieval-dependent methods (like FactTune-FS) while being significantly more efficient during training
Breakthrough Assessment
8/10
Strong conceptual contribution by decoupling factuality enforcement from expensive external retrieval during RL. The 'Checklist' approach effectively operationalizes the 'knowledge boundary' concept for practical training.