📝 Paper Summary
Mechanistic Interpretability
Knowledge Storage and Retrieval
Transformer Circuit Analysis
Factual recall in LLMs is performed by four distinct mechanisms (Subject Heads, Relation Heads, Mixed Heads, MLPs) that additively combine to boost the correct answer.
Core Problem
While prior work localized knowledge to early MLP layers, it remained unclear how models move and use this information to surface specific facts in the final output.
Why it matters:
- Understanding how LLMs store and retrieve knowledge is crucial for interpretability, safety, and editing model behaviors
- Narrow circuit analysis often neglects secondary information sources (like relation tokens), leading to incomplete understandings of model predictions
- Phenomena like the 'reversal curse' (A is B does not imply B is A) lack a clear mechanistic explanation
Concrete Example:
For the prompt 'Fact: The Colosseum is in the country of', the model must combine information about the subject 'Colosseum' (e.g., implies Italy, Rome) and the relation 'country' (e.g., implies Italy, Spain) to output 'Italy' rather than 'Rome' or 'Spain'.
Key Novelty
The Additive Motif for Factual Recall
- LLMs solve factual recall using multiple independent components (Subject Heads, Relation Heads, Mixed Heads, MLPs) that individually push for different attribute sets but constructively interfere on the correct answer
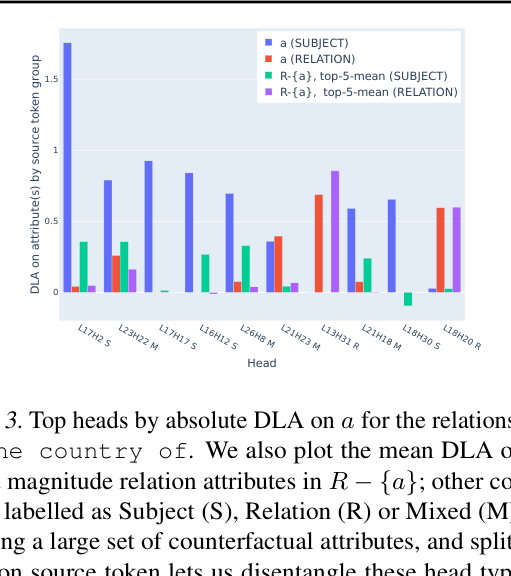
- Introduces 'DLA by source token group' to disentangle Mixed Heads, showing they are sums of separate updates from Subject and Relation tokens
Architecture
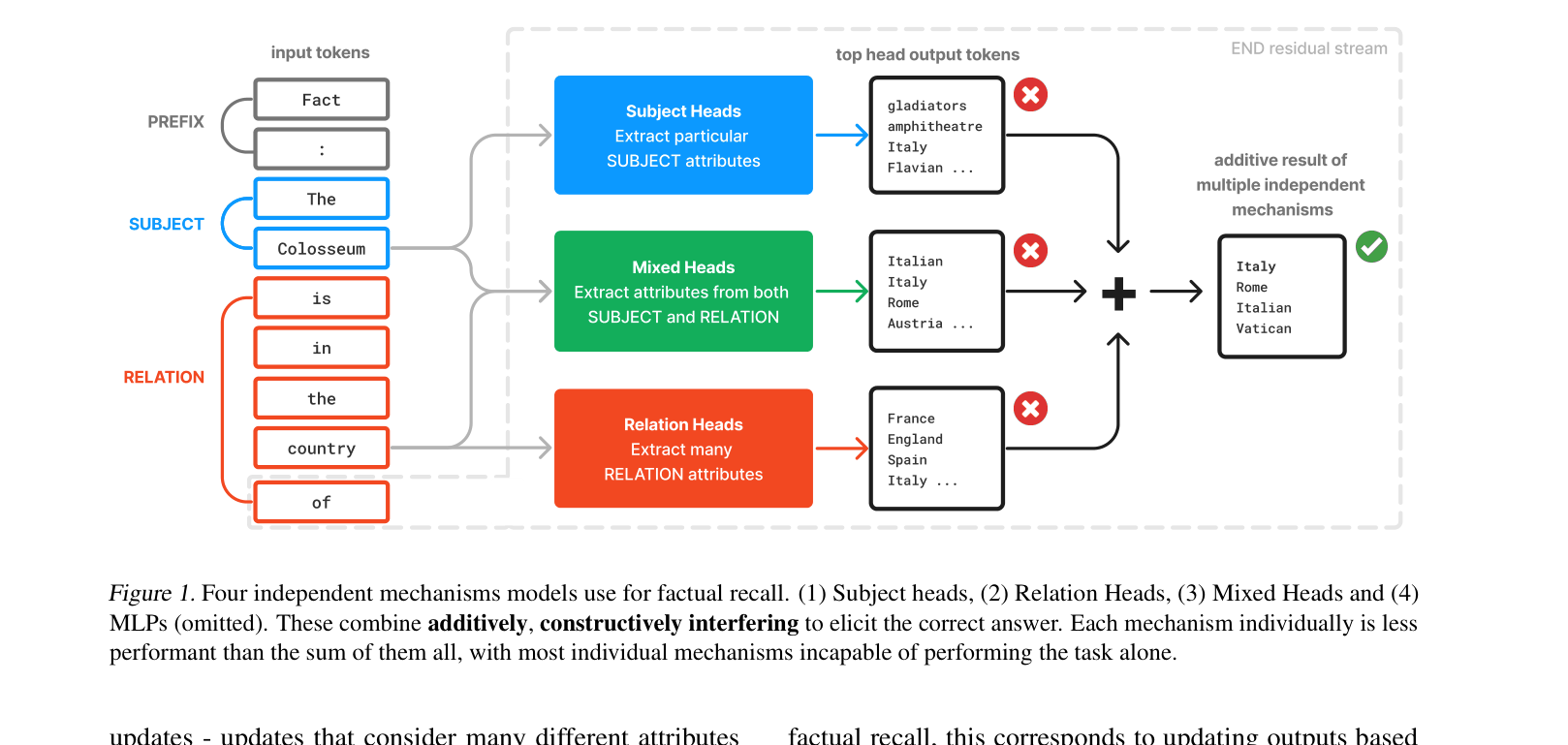
A conceptual diagram of the four independent mechanisms (Subject Heads, Relation Heads, Mixed Heads, MLPs) contributing to the final output.
Evaluation Highlights
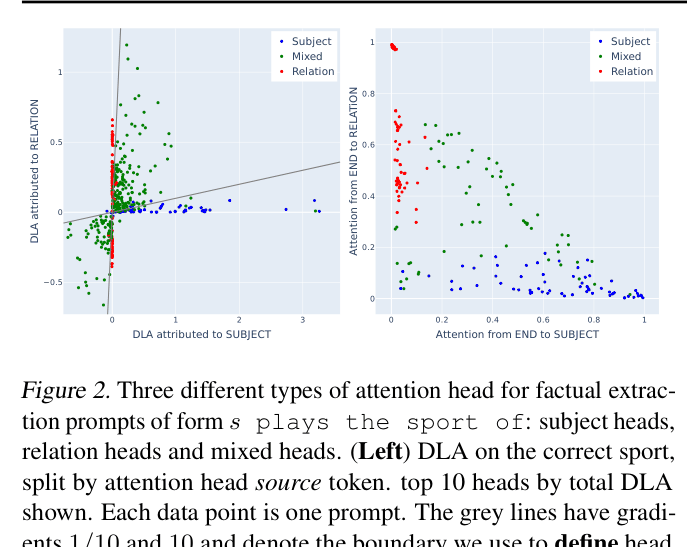
- Identified distinct 'Subject Heads' (ratio > 10 subject/relation DLA) that extract attributes regardless of the relation prompt
- Identified distinct 'Relation Heads' (ratio > 10 relation/subject DLA) that extract relation targets regardless of the subject
- Demonstrated that 'Mixed Heads' act as the sum of both subject and relation extractions, attending to both positions simultaneously
Breakthrough Assessment
7/10
Provides a significant advance in mechanistic understanding of factual recall by decomposing it into additive components, though limited to a small dataset and specific model (Pythia-2.8b).