📝 Paper Summary
Factuality Evaluation
Hallucination Detection
The authors introduce a 3D (Decompose, Decouple, Detach) paradigm to evaluate the factuality of subjective, interpretive AI claims in contact center conversations, releasing a benchmark dataset (FECT) grounded in this method.
Core Problem
Evaluating the factuality of AI-generated summaries for contact center conversations is difficult because claims are often analytical interpretations (e.g., sentiment, root cause) rather than verbatim facts, lacking clear ground truth.
Why it matters:
- Traditional hallucination detection relies on direct fact-checking against explicit evidence, which fails for subjective interpretations common in enterprise analysis
- Ambiguity in analytical claims leads to low human inter-annotator agreement, making it impossible to reliably evaluate or improve AI systems in high-stakes business contexts
Concrete Example:
A claim stating 'The customer chose the plan for specific dentist coverage' might be true based on implied context (a mention of a 'particular dentist' followed by a plan change), but lacks explicit text evidence. Without a structured framework, one annotator might mark this factual while another marks it hallucinated due to the subjective inference required.
Key Novelty
3D Paradigm (Decompose, Decouple, Detach)
- Decompose claims into minimal units, Decouple concrete terms from subjective interpretations, and Detach structure from meaning to verify relations
- Applies linguistic principles (constituency, compositionality) to ground human and LLM judgments, significantly improving agreement on subjective claims
Architecture
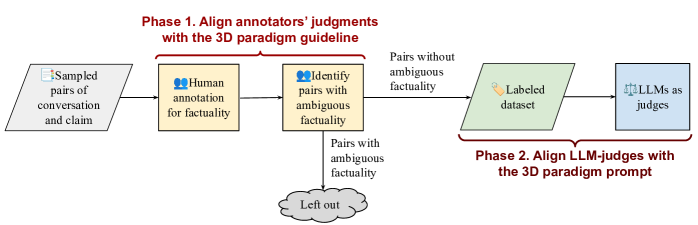
The workflow for developing the FECT dataset and aligning LLM-judges.
Evaluation Highlights
- Achieved 0.82 inter-annotator agreement (Cohen's kappa) among human experts using the 3D paradigm, up from 0.28 with unguided labeling
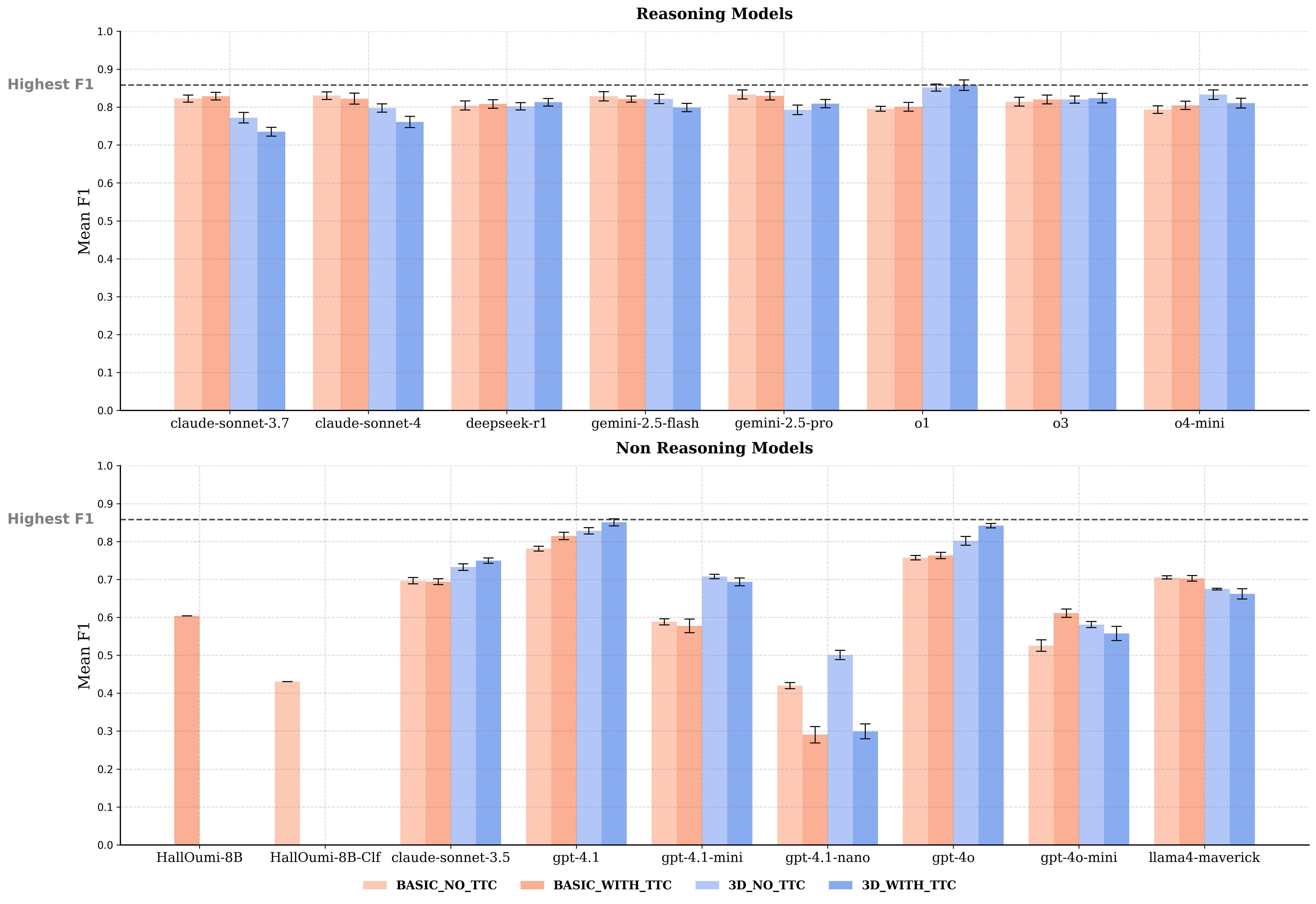
- OpenAI o1 model aligned on the 3D paradigm achieved 0.86 F1 score on the FECT benchmark without fine-tuning
- Reasoning models (like o1) outperform non-reasoning models significantly on this task, with a +0.17 F1 gap between o1 and GPT-4o
Breakthrough Assessment
8/10
Addresses a neglected but critical area of hallucination detection (interpretive claims) with a rigorous linguistic framework. The high human agreement improvement validates the method's effectiveness.