📝 Paper Summary
Hallucination suppression
Decoding-time intervention
CDT reduces hallucinations by guiding language model decoding away from a fine-tuned hallucinatory comparator and towards a truthful one, using a mixture-of-experts strategy to handle diverse task patterns.
Core Problem
LLMs suffer from multifaceted hallucinations (both intrinsic and faithful) across different tasks, and existing methods often compromise internal knowledge or fail to address coupled hallucination patterns simultaneously.
Why it matters:
- Hallucinations severely limit model credibility in realistic applications by generating plausible but non-factual claims.
- Secondary training for factuality is labor-intensive and can inadvertently encourage spurious patterns.
- Existing editing methods may interfere with internal factual knowledge, causing performance bottlenecks on out-of-distribution tasks.
Concrete Example:
In text summarization, a model like LLaMA2-7B-Chat might exhibit 'faithful hallucination' (wrongly extracting information) and 'intrinsic hallucination' (fabricating false content not in the document) simultaneously in the same response, which simple penalty methods fail to distinguish.
Key Novelty
Comparator-driven Decoding-Time (CDT) framework
- Constructs two distinct comparator models (hallucinatory and truthful) via multi-task fine-tuning to model negative and positive generation attributes separately.
- Uses an Instruction Prototype-guided Mixture of Experts (PME) strategy within the comparators to dynamically activate different LoRA adapters based on the specific hallucination pattern of the current task.
- Modifies the final output probability distribution during inference by contrasting the target model against both comparators, penalizing the hallucinatory distribution and boosting the truthful one.
Architecture
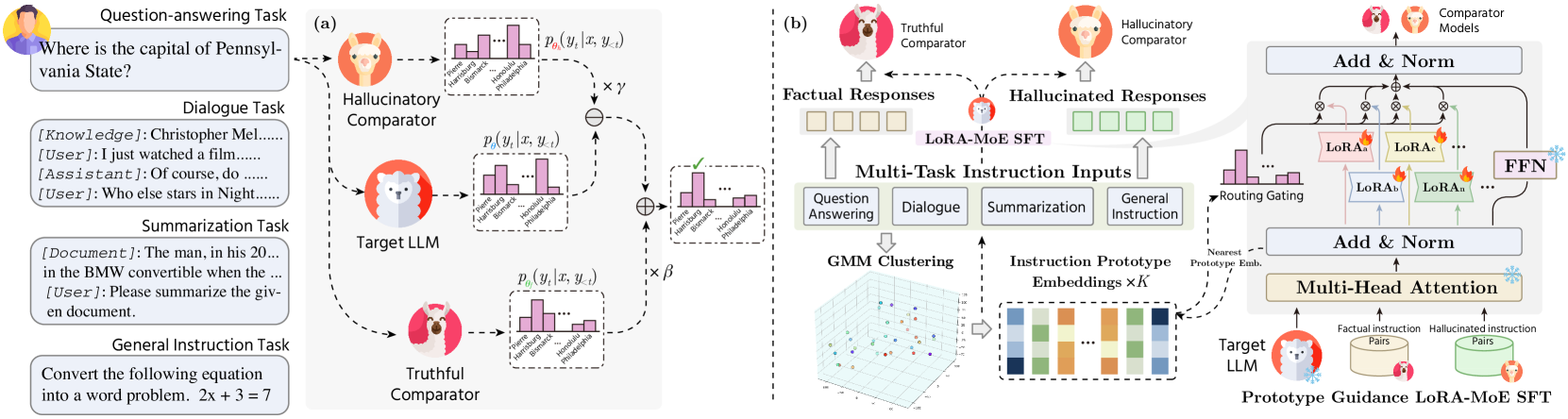
The overall CDT framework, illustrating the parallel decoding process where the Target LLM, Truthful Comparator, and Hallucinatory Comparator all process the input. It details the Instruction Prototype-guided Mixture of Experts (PME) module within the comparators.
Evaluation Highlights
- +5.49 improvement on ROUGE-L for LLaMA2-7B-Chat on the XSum summarization task compared to the base model.
- Outperforms the strong baseline ICD by ~1-3 points across multiple metrics (ROUGE, BERTScore) on standard benchmarks.
- Achieves consistent gains across four diverse tasks (TruthfulQA, XSum, WoW, HaluEval) using the same framework.
Breakthrough Assessment
7/10
Offers a robust decoding-time solution that handles multifaceted hallucinations via a novel mixture-of-experts approach. While effective, it relies on constructing specific comparator models, adding some complexity compared to simple penalty methods.