📝 Paper Summary
Modularized RAG pipeline
Hallucination suppression
BRIDGE is a framework that dynamically weights internal versus external knowledge reliance and selects optimal response strategies (including refusal) to handle conflicting or unreliable information in RAG systems.
Core Problem
RAG models struggle to balance internal parametric knowledge with retrieved external knowledge, often failing when sources conflict, contain errors, or when both are unreliable.
Why it matters:
- Current systems often blindly trust retrieval (vulnerable to poisoning) or stubbornly hold outdated internal beliefs, lacking flexibility
- Existing approaches typically address single scenarios (e.g., always retrieving or always refusing) but lack a unified framework for all real-world conditions
- Refusal mechanisms are critical for safety but are frequently overlooked in standard RAG pipelines, leading to hallucinations when no good information exists
Concrete Example:
For the question 'What is the CPU of iPhone 16?', a model with a 2023 cutoff has no internal knowledge. If retrieval returns poisoned text saying 'A17', standard RAG generates the wrong answer. Ideally, the model should verify evidence and refuse to answer if neither source is credible.
Key Novelty
Biased Retrieval and Generation Evaluation (BRIDGE)
- Introduces 'soft bias': an adaptive weighting mechanism that predicts how much a question relies on retrieval vs. internal knowledge before generation
- Uses a multi-granularity scorer to compare internal knowledge, external knowledge, and generated sub-queries to detect consistency
- Selects the final strategy (Faithful to Internal, Faithful to External, or Refuse) via an interpretable decision tree based on trust scores
Architecture
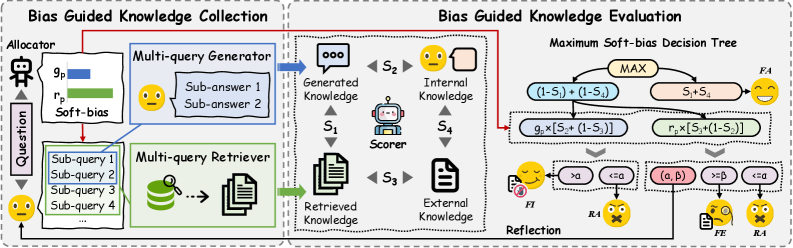
The BRIDGE framework workflow, detailing the two main stages: Bias-Guided Knowledge Collection and Bias-Guided Knowledge Evaluation.
Evaluation Highlights
- Outperforms baselines by 5–15% in accuracy on the proposed TRD benchmark while maintaining balanced performance across scenarios
- Achieves superior refusal rates when appropriate (Refuse-to-Answer scenario), whereas standard RAG baselines refuse <10% of the time
- Demonstrates robustness by improving performance on out-of-domain datasets (RealtimeQA, HotpotQA-Poisoned) using hyperparameters tuned only on TRD
Breakthrough Assessment
8/10
Offers a comprehensive solution to the 'knowledge conflict' problem in RAG by unifying refusal, internal adherence, and external adherence into one framework. The construction of the TRD benchmark is also a significant contribution.