📝 Paper Summary
Hallucination suppression
Uncertainty estimation
FactTest is a statistical hypothesis testing framework that calibrates LLM refusal thresholds to strictly control the probability of incorrectly marking hallucinations as factual (Type I error).
Core Problem
Existing hallucination detection methods lack formal guarantees for error control, making them unreliable for high-stakes domains where incorrectly flagging a hallucination as truth (Type I error) is dangerous.
Why it matters:
- High-stakes applications like healthcare and law require rigorous verification; a model confidently stating incorrect medical advice is far worse than abstaining.
- Current uncertainty estimation methods provide scores but lack a theoretical framework to set thresholds that guarantee a specific maximum error rate.
- Resource-intensive fine-tuning or retrieval-based methods are often impractical for black-box models or low-resource settings.
Concrete Example:
A user asks an LLM for a specific legal precedent. A standard model might hallucinate a non-existent case with high confidence. FactTest evaluates the model's certainty and, if the statistical test fails to reject the null hypothesis (uncertainty), forces the model to abstain rather than present the hallucination as fact.
Key Novelty
Hypothesis Testing for LLM Factuality
- Formulates factuality assessment as a Neyman-Pearson classification problem: the null hypothesis is that the generated answer is uncertain/incorrect.
- Uses a small calibration set to dynamically select a certainty score threshold that guarantees the False Positive Rate (claiming a hallucination is true) stays below a user-defined alpha.
- Provides finite-sample guarantees that work for any model (black-box or white-box) and extends to covariate shift scenarios via density ratio estimation.
Architecture
The FactTest workflow compared to standard generation. It shows the process of generating an answer, calculating a certainty score, and using a calibrated threshold to decide between outputting the answer or abstaining.
Evaluation Highlights
- Achieves >40% accuracy improvement on QA benchmarks (TriviaQA, SQuAD) compared to pretrained models by effectively abstaining from unknown questions.
- Outperforms fine-tuned baselines (like R-Tuning) by ~30% in accuracy while utilizing only half the amount of training data.
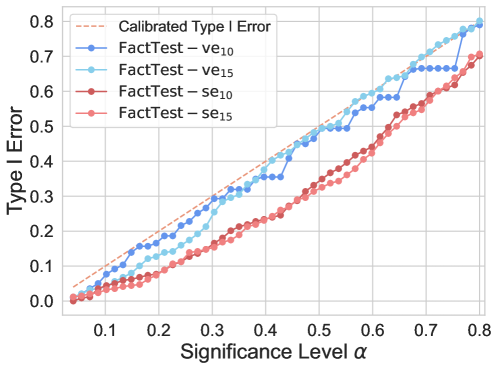
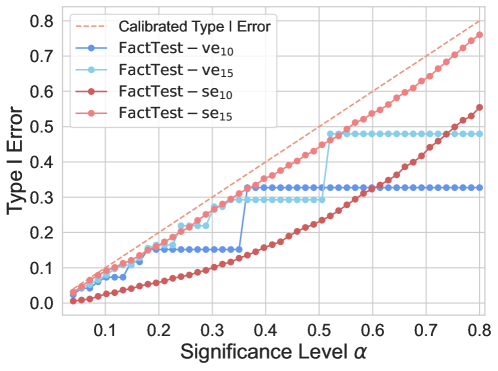
- Maintains strict control of Type I error (hallucinations flagged as factual) below the user-specified significance level (e.g., alpha=0.1) across various datasets.
Breakthrough Assessment
8/10
Introduces a rigorous statistical foundation to hallucination detection, moving beyond heuristic thresholding. The finite-sample guarantees are a significant theoretical contribution for reliable AI deployment.