📝 Paper Summary
Reinforcement Learning for Factuality
Slow-thinking Models (Reasoning Models)
KnowRL mitigates hallucinations in slow-thinking models by integrating a factuality verification reward directly into the reinforcement learning process, encouraging models to verify intermediate reasoning steps against external knowledge.
Core Problem
Slow-thinking models trained with outcome-based RL often generate correct final answers via hallucinated or factually incorrect reasoning chains, reinforcing unreliable thinking patterns.
Why it matters:
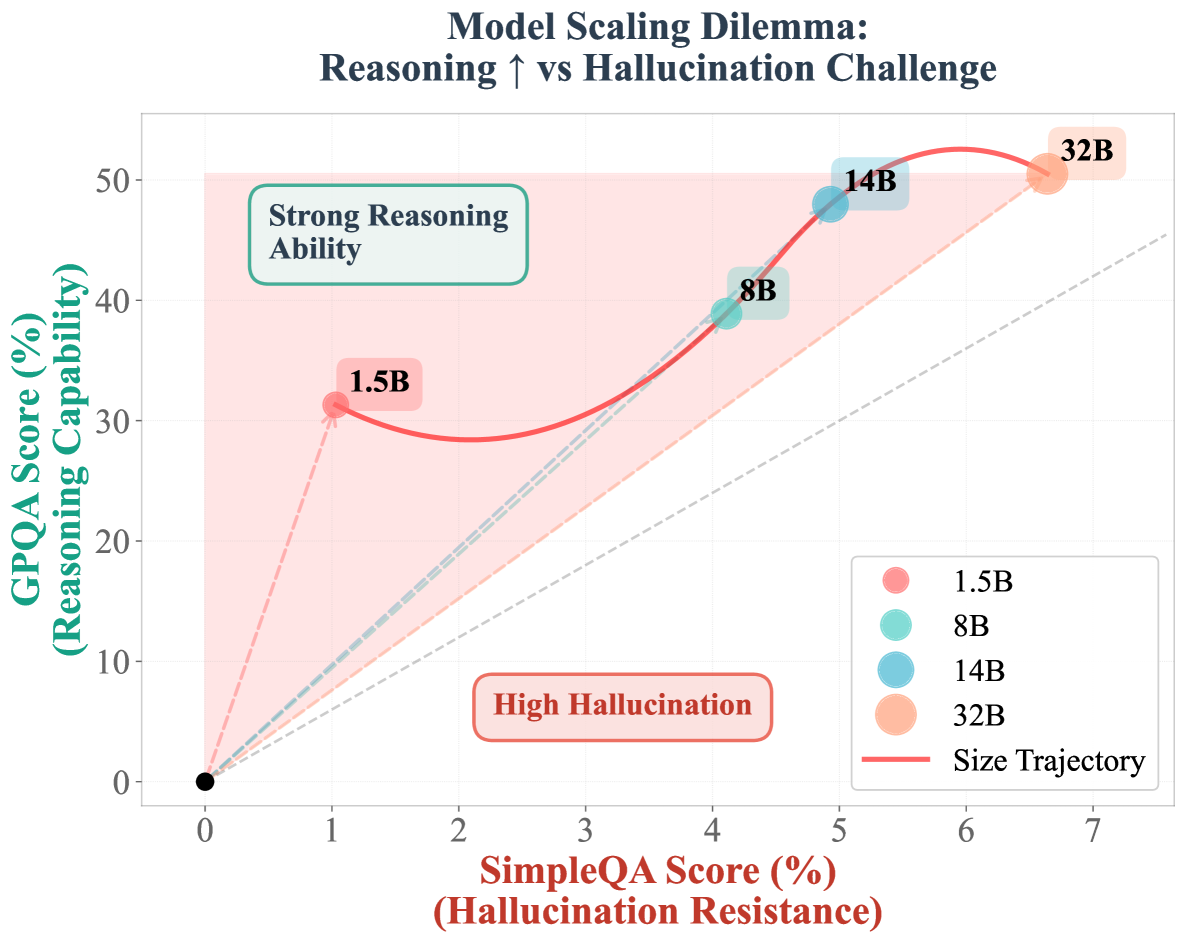
- Scaling reasoning models (like DeepSeek-R1-Distill) improves complex problem-solving but often exacerbates hallucinations on simple factual tasks due to a lack of process supervision
- Outcome-based rewards ignore the factual validity of the intermediate 'thought' process, allowing models to memorize answers while fabricating the logic
- Existing fixes like RAG or SFT are either costly to scale or disrupt the reasoning strategies learned during RL
Concrete Example:
A model might answer a question correctly but justify it with a fabricated date or event in its chain-of-thought. Outcome-based RL rewards this 'lucky' success, reinforcing the habit of making up facts to reach a goal.
Key Novelty
Factuality-Supervised Group Relative Policy Optimization (GRPO)
- Incorporates a fine-grained 'factuality reward' into the RL loop by decomposing reasoning traces into atomic facts and verifying them against a knowledge base
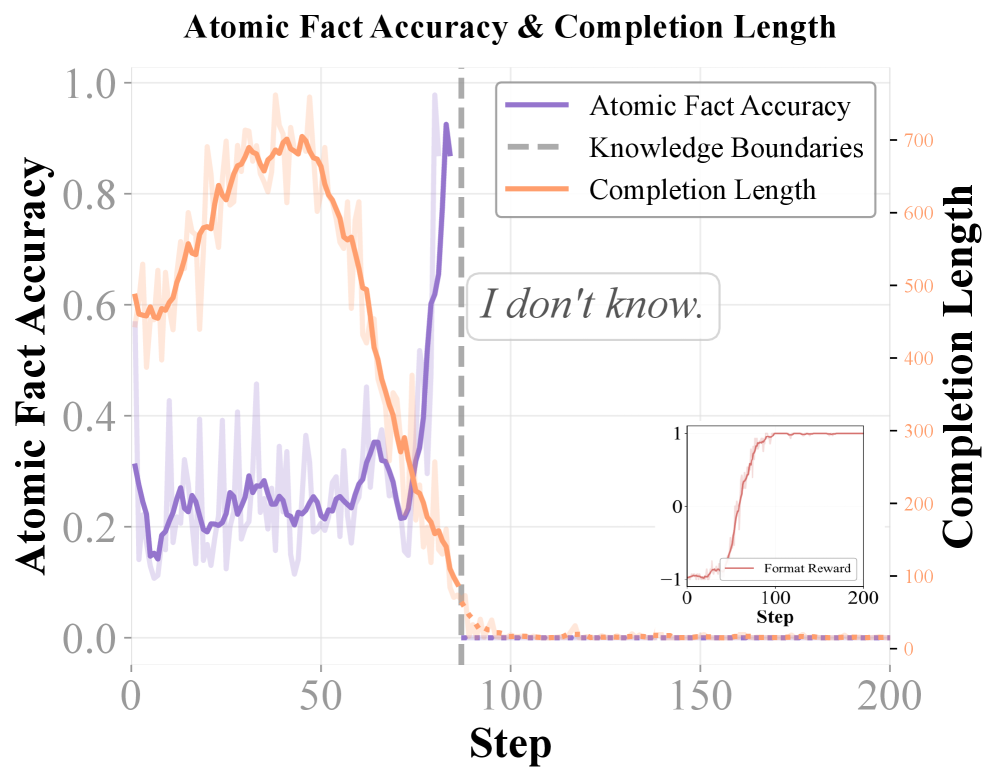
- Rewards models not just for the correct answer, but for the proportion of verifiable facts in their reasoning chain, and rewards explicit refusals when knowledge is insufficient
Architecture
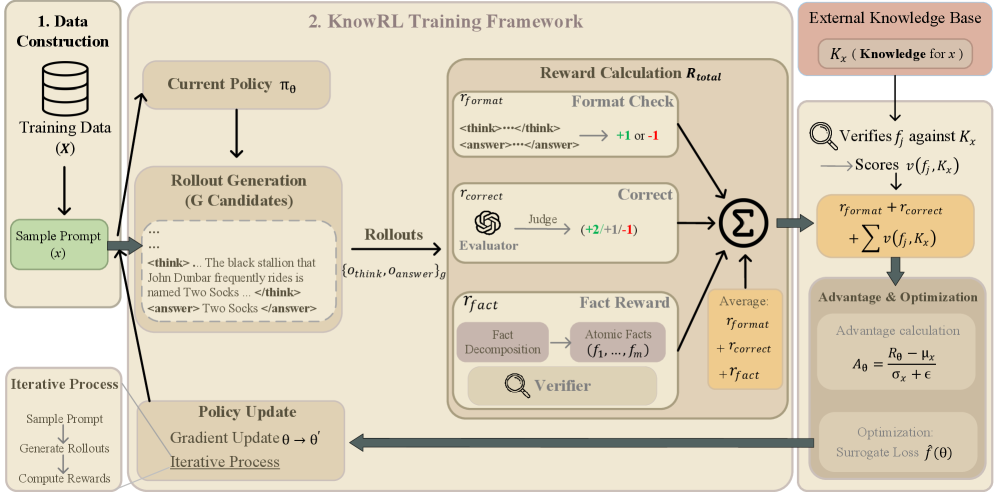
The KnowRL framework workflow: Fact-grounded data construction, RL training loop with factuality verification, and policy update.
Evaluation Highlights
- Reduces Incorrect Rate on SimpleQA by 20.3 percentage points (from 78.00% to 57.67%) for DeepSeek-R1-Distill-Qwen-7B
- Maintains strong reasoning ability on GPQA (improving from 37.37% to 42.42%) while significantly reducing hallucinations
- Achieves consistent gains on ChineseSimpleQA (Incorrect Rate -10.0%), demonstrating transfer of boundary-aware behaviors beyond the English training knowledge base
Breakthrough Assessment
8/10
Effective method for fixing the specific 'reasoning-hallucination trade-off' in slow-thinking models. Directly addressing the RL reward signal for intermediate steps is a high-value contribution.