📊 Experiments & Results
Evaluation Setup
Explainable recommendation on Amazon Reviews categories. Models generate explanations which are compared against constructed statement-level ground truths.
Benchmarks:
- Amazon Reviews (Toys, Clothes, Beauty, Sports, Cellphones) (Explanation Generation)
Metrics:
- Statement-to-Explanation Precision (St2Exp-P)
- Statement-to-Explanation Recall (St2Exp-R)
- Statement-to-Explanation F1 (St2Exp-F1)
- Statement Entailment Precision (StEnt-P)
- Statement Coherence (StCoh)
- BERTScore F1
- BLEURT
- Statistical methodology: Standard deviations reported across samples.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| High semantic similarity scores across models contrast sharply with low factual consistency scores. | ||||
| Amazon Sports | BERTScore F1 | Not reported in the paper | 0.90 | Not reported in the paper |
| Amazon Sports | St2Exp-P | 5.38 | 32.88 | +27.50 |
| Amazon Beauty | St2Exp-R | 13.08 | 29.86 | +16.78 |
| Amazon Toys | St2Exp-P | 16.63 | 25.27 | +8.64 |
| Amazon Cellphones | StEnt-P | 20.77 | 24.80 | +4.03 |
| Amazon Clothes | StCoh-P | -1.04 | 3.31 | +4.35 |
Experiment Figures
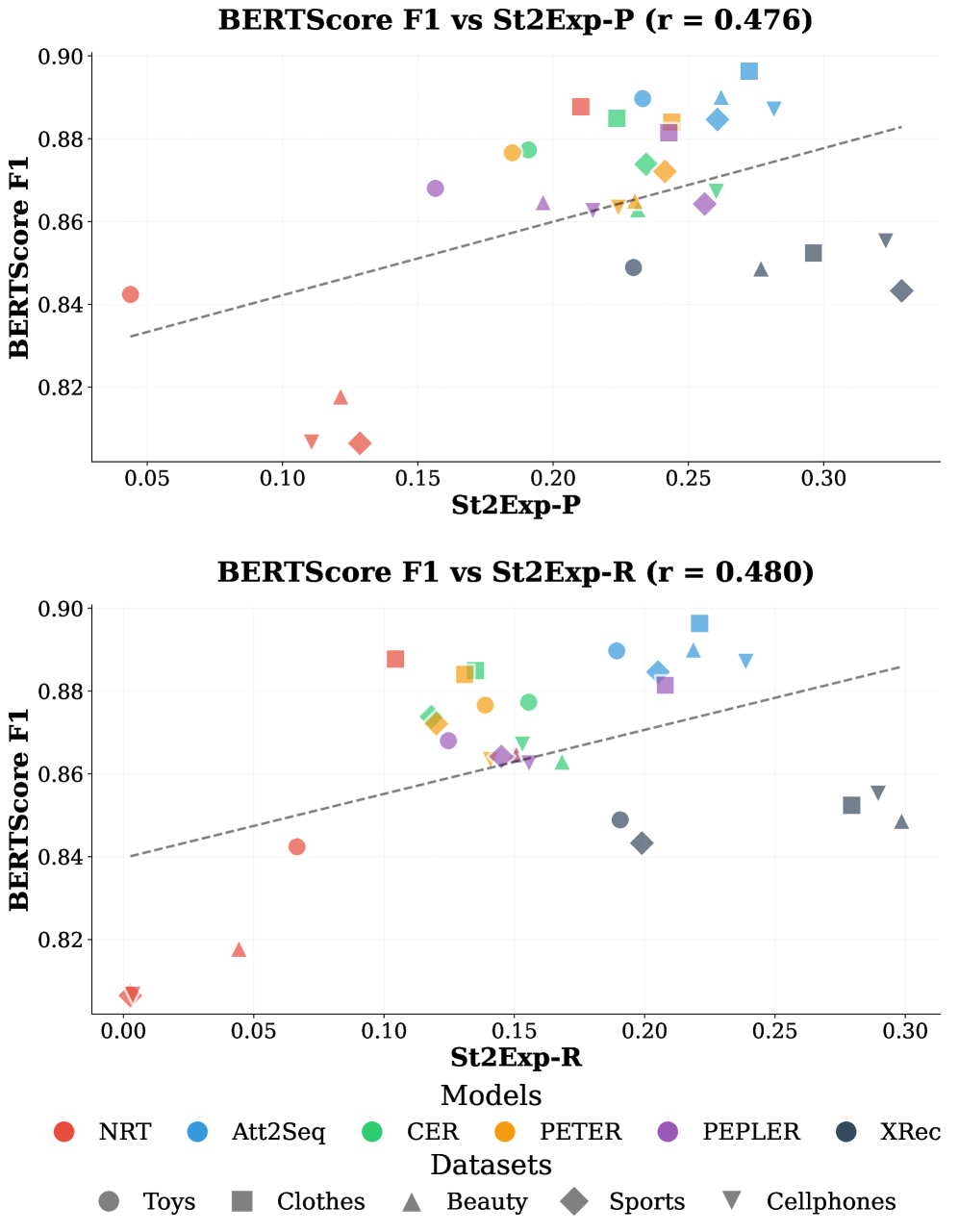
Radar chart comparing BERTScore F1 vs Statement-level Precision (St2Exp-P) across 6 models on the Amazon Sports dataset.
Main Takeaways
- Massive gap between semantic similarity (BERTScore ~0.9) and factual accuracy (<33%), indicating current models hallucinate explanations that look good but are factually unsupported.
- LLM-based models (XRec) generally outperform RNN/Transformer baselines in factuality, but still fail to recover the majority of ground truth statements (Recall < 30%).
- NLI metrics show that models often generate contradictory statements (negative coherence scores), a failure mode not captured by standard similarity metrics.
- Transformer-based models (PEPLER) excel at mimicking review style (high BLEURT) but do not necessarily ensure factual consistency.