📝 Paper Summary
Long-form factuality evaluation
Fact extraction and verification
Hallucination detection
VeriFact improves long-form factuality evaluation by using LLMs to refine extracted facts (adding context and relations) and introduces FactRBench to measure both precision and recall using reference fact sets.
Core Problem
Existing evaluation pipelines (decompose-decontextualize-verify) often fail on long-form text because they extract incomplete facts lacking necessary context or miss facts representing inter-sentence relations.
Why it matters:
- Incomplete facts (e.g., 'price could drop 50%') without conditions (e.g., 'if demand disappears') lead to incorrect verification verdicts.
- Current methods focus almost exclusively on precision, neglecting recall (coverage of relevant facts), which is critical for comprehensive assessment.
- Fixed-K metrics like F1@K are question-agnostic and may misrepresent factual coverage for complex queries.
Concrete Example:
For a query about gold prices, the SAFE method extracts 'The price of gold could drop by 20-50%', losing the critical condition 'if the demand for gold as jewelry were to disappear'. This omission causes the verifier to label the fact incorrectly. SAFE also misses the causal relation that this drop would happen 'making' it similar to other metals.
Key Novelty
VeriFact (Verification of refined Facts) & FactRBench
- Introduces a refinement step in the extraction pipeline where LLMs explicitly detect and repair 'incomplete facts' (missing context/conditions) and 'missing facts' (overlooked relational info).
- Creates FactRBench, a benchmark with reference fact sets derived from human answers and aggregated LLM outputs, enabling the calculation of recall alongside precision.
- Releases full web pages used for verification to ensure reproducibility, unlike prior benchmarks that rely on transient search results.
Architecture
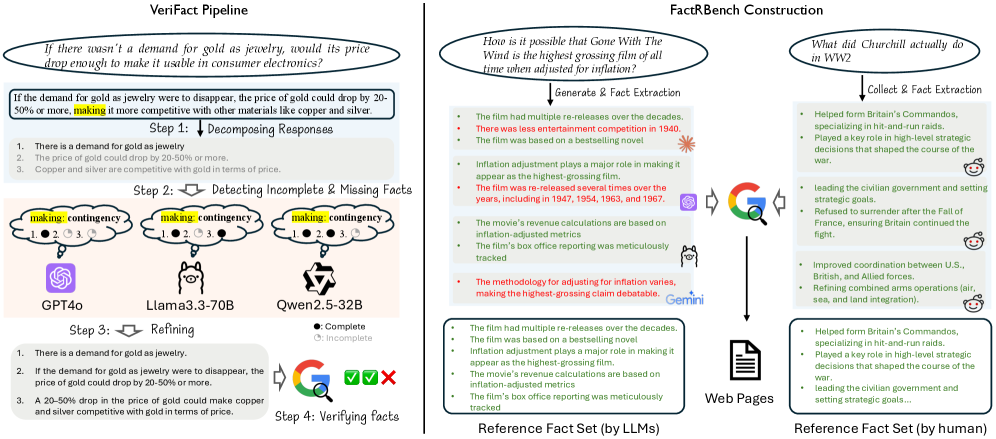
The VeriFact pipeline workflow.
Evaluation Highlights
- VeriFact reduces the extraction of incomplete facts by 19.2% compared to the best comparison method (SAFE).
- The refinement stage reduces the number of missing facts by 37%, capturing more inter-sentence dependencies.
- Ensemble LLM annotation achieves 0.89 recall for detecting incomplete facts and 0.85 recall for missing facts.
Breakthrough Assessment
8/10
Significantly refines the standard factuality pipeline by addressing the 'context loss' problem in atomic fact extraction and rigorously introducing recall metrics, which are often ignored in hallucination research.
