📝 Paper Summary
RAG robustness
Context utilisation
CUB is a comprehensive benchmark evaluating seven context manipulation techniques across nine language models to diagnose how well they handle relevant, conflicting, and irrelevant information in retrieval-augmented generation.
Core Problem
Language models in RAG systems often ignore relevant information that conflicts with their internal memory or get distracted by irrelevant contexts, and existing mitigation techniques are evaluated in isolation on narrow tasks.
Why it matters:
- Real-world retrieval systems are imperfect and often return irrelevant data, distracting the model from the correct answer
- Information changes over time (e.g., a new Prime Minister), requiring models to prioritize retrieved context over outdated internal memory
- Current evaluations are fragmented, making it unclear which techniques work across diverse scenarios like gold, conflicting, and irrelevant contexts
Concrete Example:
When asked a question where the answer has changed (e.g., 'Who is the CEO of X?'), a model might ignore the retrieved document stating the new CEO (conflicting context) and hallucinate the old CEO from its training data. Conversely, if the retrieval system returns a document about a different company (irrelevant context), the model might mistakenly use that information instead of its correct internal knowledge.
Key Novelty
Context Utilisation Benchmark (CUB)
- First unified benchmark explicitly designed to diagnose Context Utilisation Manipulation Techniques (CMTs) across three distinct context types: gold (relevant), conflicting (contradicts memory), and irrelevant (noise)
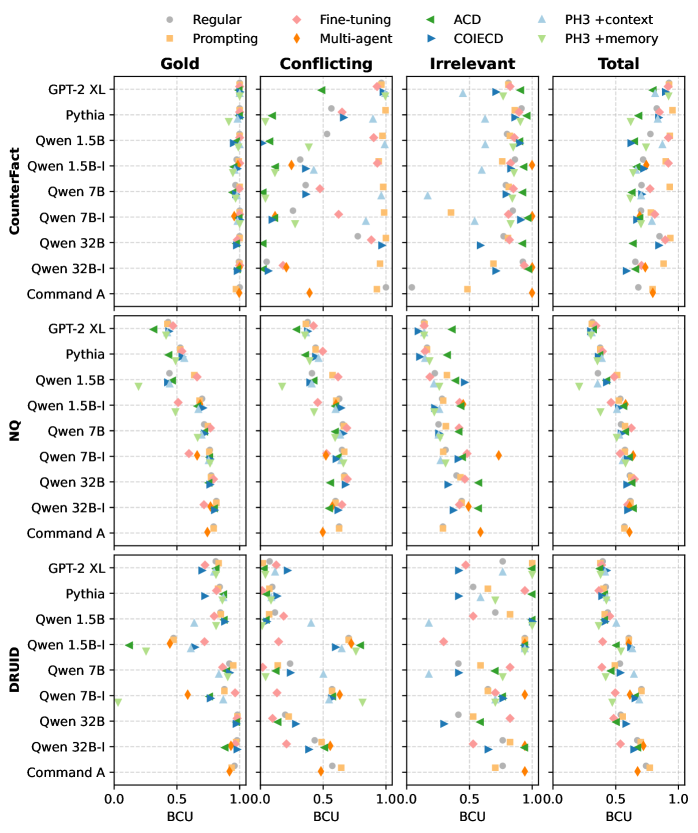
- Systematic evaluation of 7 diverse CMTs (prompting, fine-tuning, decoding, mechanistic) across 9 LMs to reveal trade-offs between robustness and faithfulness
Architecture
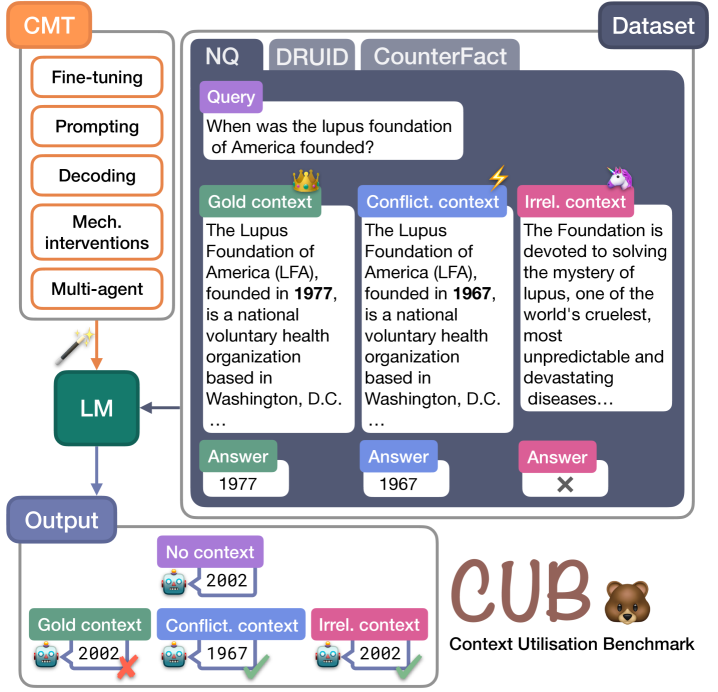
Overview of the CUB benchmark framework showing the input types, diverse LMs, and the 7 CMTs being evaluated.
Evaluation Highlights
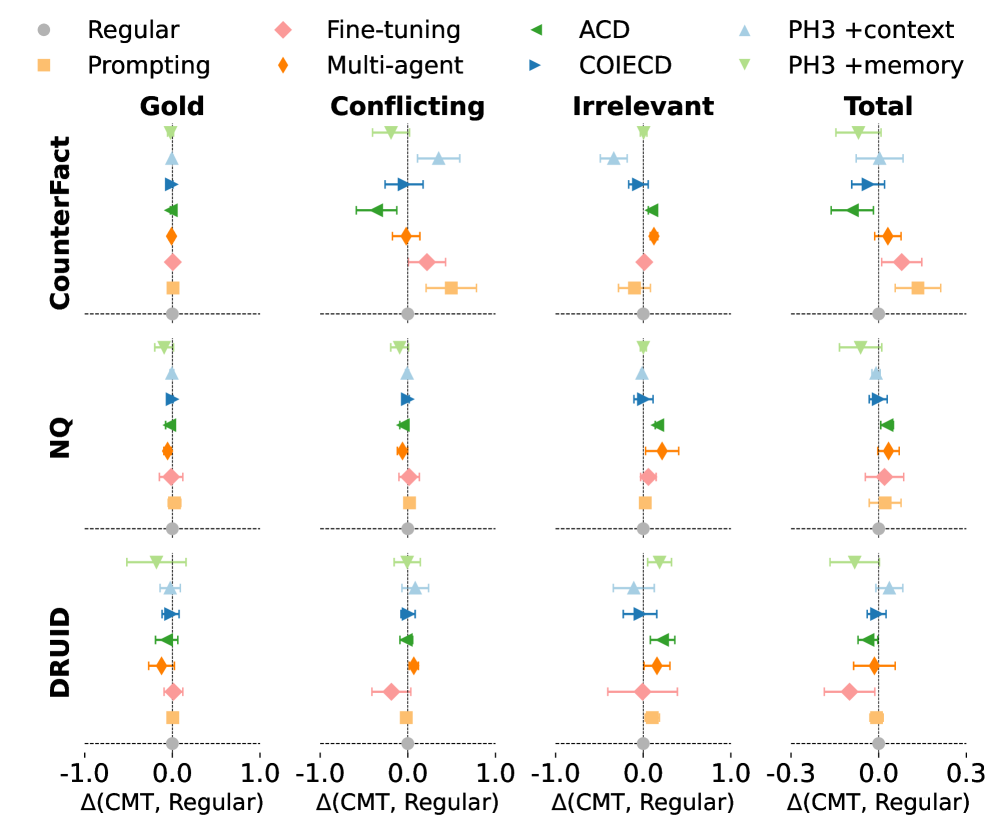
- No single technique excels everywhere: PH3+context improves faithfulness to conflicting contexts but degrades performance on irrelevant contexts compared to regular decoding
- Regular model performance on the CounterFact dataset decreases as model size increases, contradicting standard scaling laws observed on NQ and DRUID
- Prompting-based methods and Multi-agent approaches show the most stable performance across all context types, avoiding the dramatic failure modes of more complex interventions
Breakthrough Assessment
8/10
Establishment of a much-needed benchmark for RAG robustness. The finding that no current method handles both conflicting and irrelevant contexts well exposes a major gap in the field.