📊 Experiments & Results
Evaluation Setup
Train on Biography generation; Evaluate on In-Domain (Bio) and Out-of-Domain (FAVA, FPQA, KUQA) datasets.
Benchmarks:
- Bio (In-Domain) (Biography Generation) [New]
- FAVA (OOD) (Long-form factuality on open-ended topics)
- FPQA (OOD) (Answering questions with false premises)
- KUQA (OOD) (Short-form knowledge questions)
Metrics:
- FActScore (factuality percentage)
- Win Rate (for FAVA)
- Exact Match / Accuracy (for FPQA/KUQA)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Initial benchmarking shows standard preference learning fails to generalize to OOD datasets. | ||||
| KUQA | Accuracy | 39.46 | 35.37 | -4.09 |
| FPQA | Accuracy | 44.67 | 36.20 | -8.47 |
| APEFT consistently improves performance across ID and OOD datasets compared to standard tuning. | ||||
| Average across 4 datasets | Factuality Score | Not reported in the paper | Not reported in the paper | +3.45 |
| FAVA | Win Rate vs Base | 44.6 | 51.5 | +6.9 |
Experiment Figures
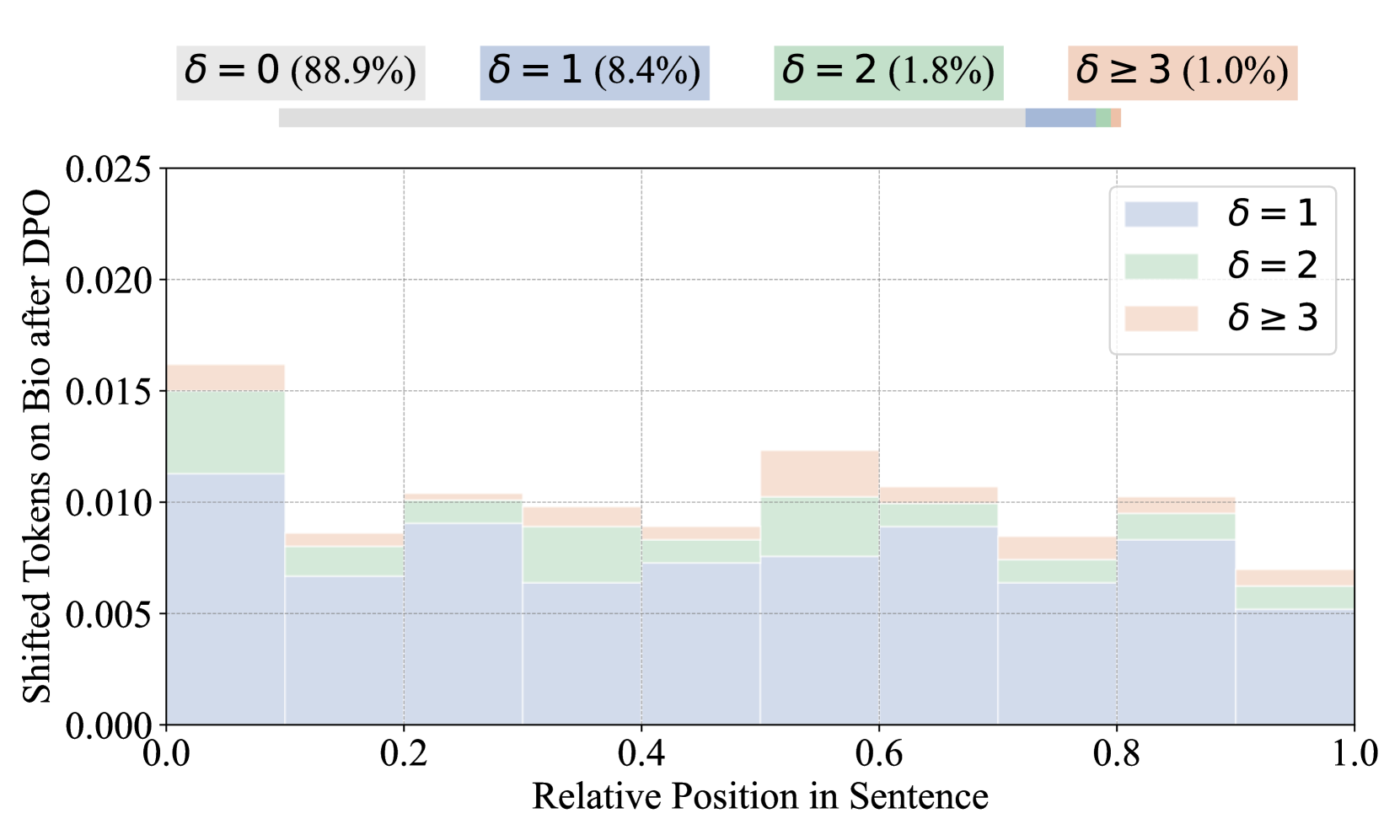
Frequency of shifted tokens (tokens with changed rank) on ID vs. OOD datasets.
Main Takeaways
- Standard preference learning (DPO, KTO, etc.) often degrades or minimally improves factuality on Out-of-Domain (OOD) tasks compared to In-Domain (ID) tasks.
- The primary cause of OOD failure is 'under-alignment'—the model changes its behavior too little—rather than 'over-alignment' to spurious features.
- APEFT, by using atomic-level preferences, forces the model to attend to fine-grained factual details, significantly mitigating under-alignment.
- Simply increasing the quantity or quality of general preference pairs does not necessarily lead to performance gains, highlighting the importance of preference granularity.