📝 Paper Summary
Dynamic Benchmarking
Knowledge Editing
Factuality Evaluation
DyKnow evaluates LLMs against Wikidata to detect outdated knowledge and assess the effectiveness of knowledge editing methods on real-world time-sensitive facts.
Core Problem
Static benchmarks for evaluating LLM factuality quickly become obsolete and cannot detect outdated knowledge, while current knowledge editing studies rely heavily on synthetic datasets rather than real-world dynamic facts.
Why it matters:
- Reliable knowledge repositories must maintain accurate, up-to-date information, but LLMs often output outdated facts based on their specific training snapshots
- Static benchmarks suffer from data contamination (leakage into future training data) and fail to capture the dynamic nature of real-world facts
- Existing editing research focuses on synthetic counterfacts, leaving a gap in understanding how editing methods perform on actual outdated knowledge in diverse domains
Concrete Example:
When asked 'Who is Cristiano Ronaldo's current football club?', an LLM trained in 2020 might confidently answer 'Juventus FC', which is outdated. DyKnow uses Wikidata's timeline to identify this as a previously correct but now outdated answer (valid 2018-2021), whereas a static benchmark might just label it 'incorrect' or fail to update the ground truth to 'Al-Nassr'.
Key Novelty
Dynamic Knowledge Benchmarking via Knowledge Graphs
- Uses Wikidata to retrieve the *current* attribute value at the exact time of evaluation, rather than relying on a static gold-standard dataset
- Retrieves a history of previously correct values with valid time intervals to distinguish between 'outdated' answers (correct in the past) and 'irrelevant' answers (hallucinations)
- Leverages the validity intervals of outdated answers to reverse-engineer and estimate the effective temporal cutoff of an LLM's pre-training data
Architecture
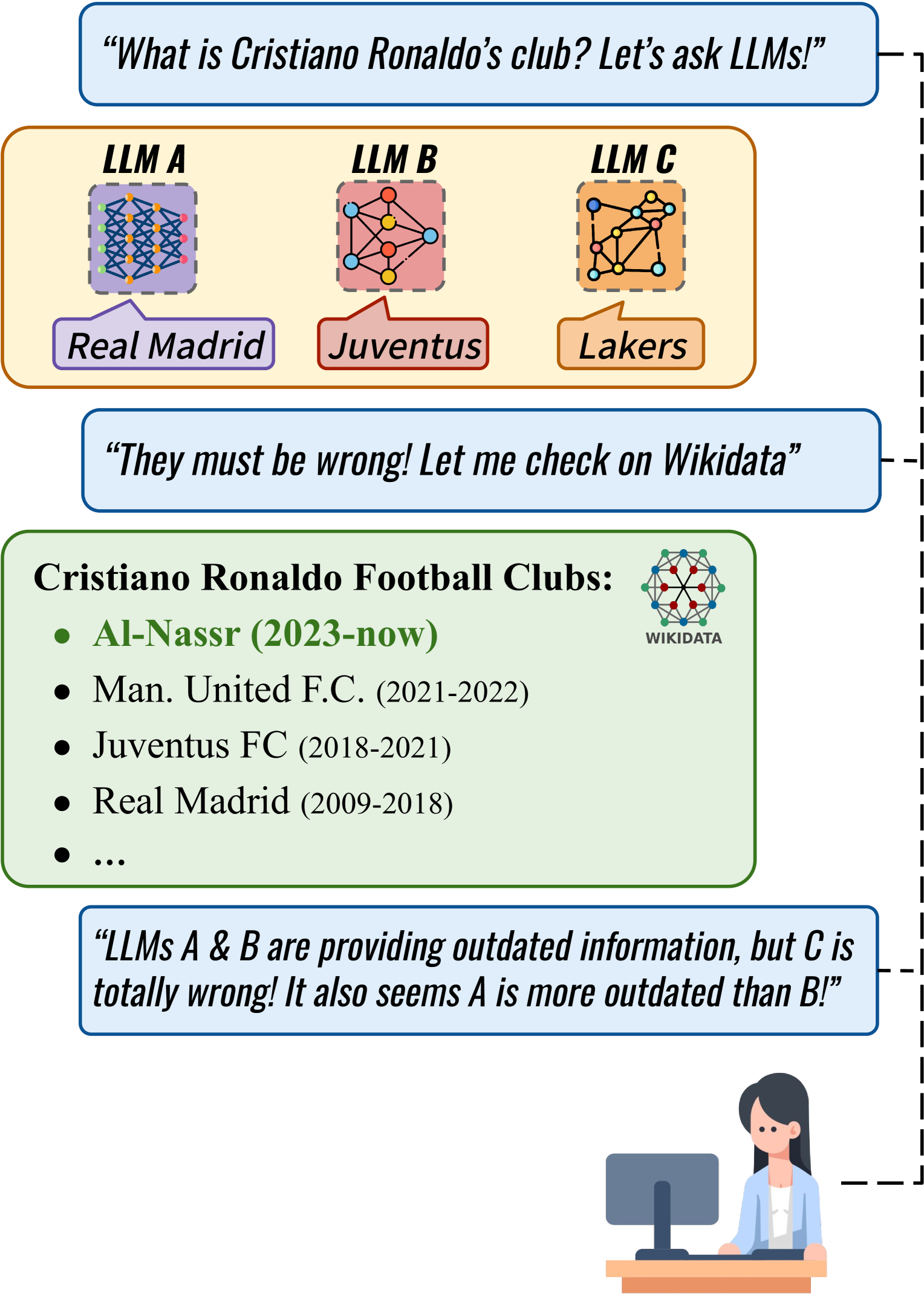
Conceptual workflow of DyKnow. It shows how a prompt (e.g., about Cristiano Ronaldo's team) is evaluated against a dynamic timeline retrieved from Wikidata.
Evaluation Highlights
- GPT-4 (2023) achieves 80% accuracy on time-sensitive facts, while Llama-3-8B-Instruct (2024) reaches 76%, yet even best models have ~15-20% outdated/irrelevant answers
- Outdatedness is severe in older models: GPT-2 (2019) provides outdated answers to 42% of questions, while newer models like OpenELM-1.1B still yield 47% outdated responses
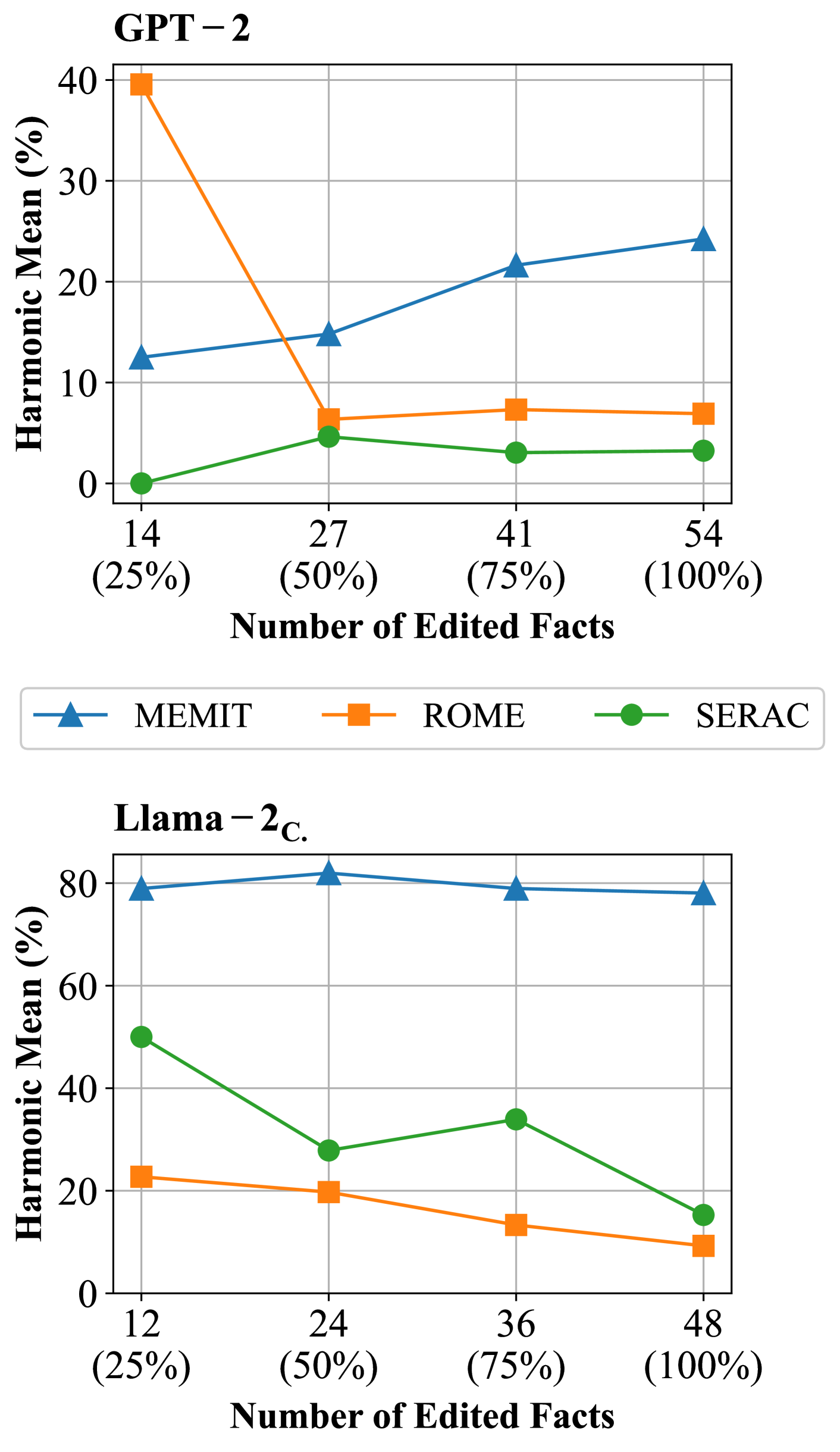
- Knowledge editing methods struggle with real-world data: ROME fails to scale, while MEMIT improves GPT-J accuracy but shows inconsistent results across different models like Llama-2-Chat
Breakthrough Assessment
7/10
Offers a practical, automated methodology for dynamic evaluation and training data dating. Highlights significant limitations in current knowledge editing methods on real data, though the scope of editing experiments is limited by compute.