📝 Paper Summary
Hallucination suppression
Factual consistency evaluation
DEEP ensembles binary outputs from diverse LLM prompts to detect factual errors in summaries, using calibration to provide reliable probability estimates without fine-tuning the underlying model.
Core Problem
Existing factual consistency models (like fine-tuned RoBERTa) rely on thresholding techniques that require access to labeled target data, which is unrealistic in practice. Furthermore, individual LLM prompts are often overconfident and fail to capture nuances.
Why it matters:
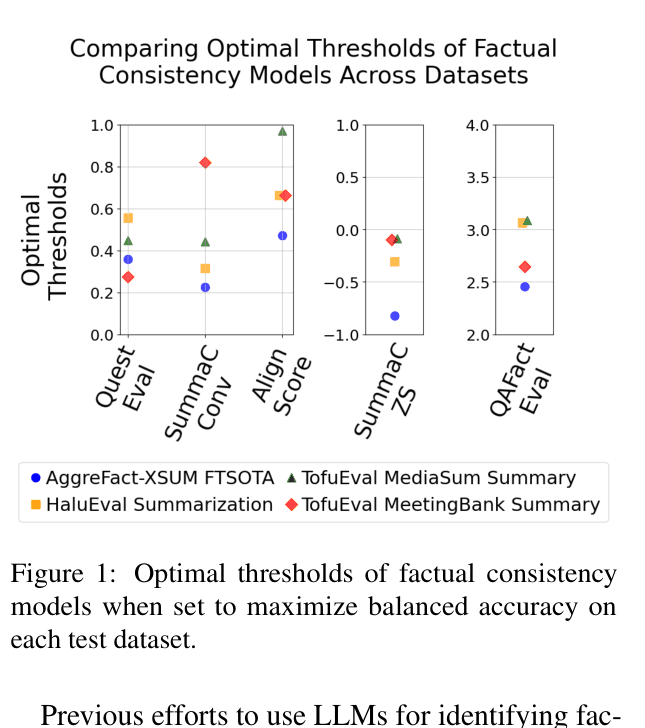
- Optimizing thresholds on test data artificially inflates performance; real-world usage requires models that work on unseen data without tuning
- Current SOTA encoder models perform significantly worse when thresholds are not optimized on the specific dataset being tested
- LLMs produce convincing but false information (hallucinations), making automated, reliable error detection critical for high-stakes summarization tasks
Concrete Example:
When evaluating the TofuEval dataset, a standard factual consistency model might need a threshold of 0.8 to work well, but on AggreFact, it might need 0.4. Without knowing the 'correct' threshold beforehand (which requires labeled data), the model's accuracy drops significantly.
Key Novelty
Ensembling diverse LLM prompts via weak supervision
- Treat the outputs of multiple, diverse LLM prompts (each checking for factuality in different ways) as binary features
- Feed these features into a lightweight ensemble model (like Snorkel's LabelModel) to aggregate predictions
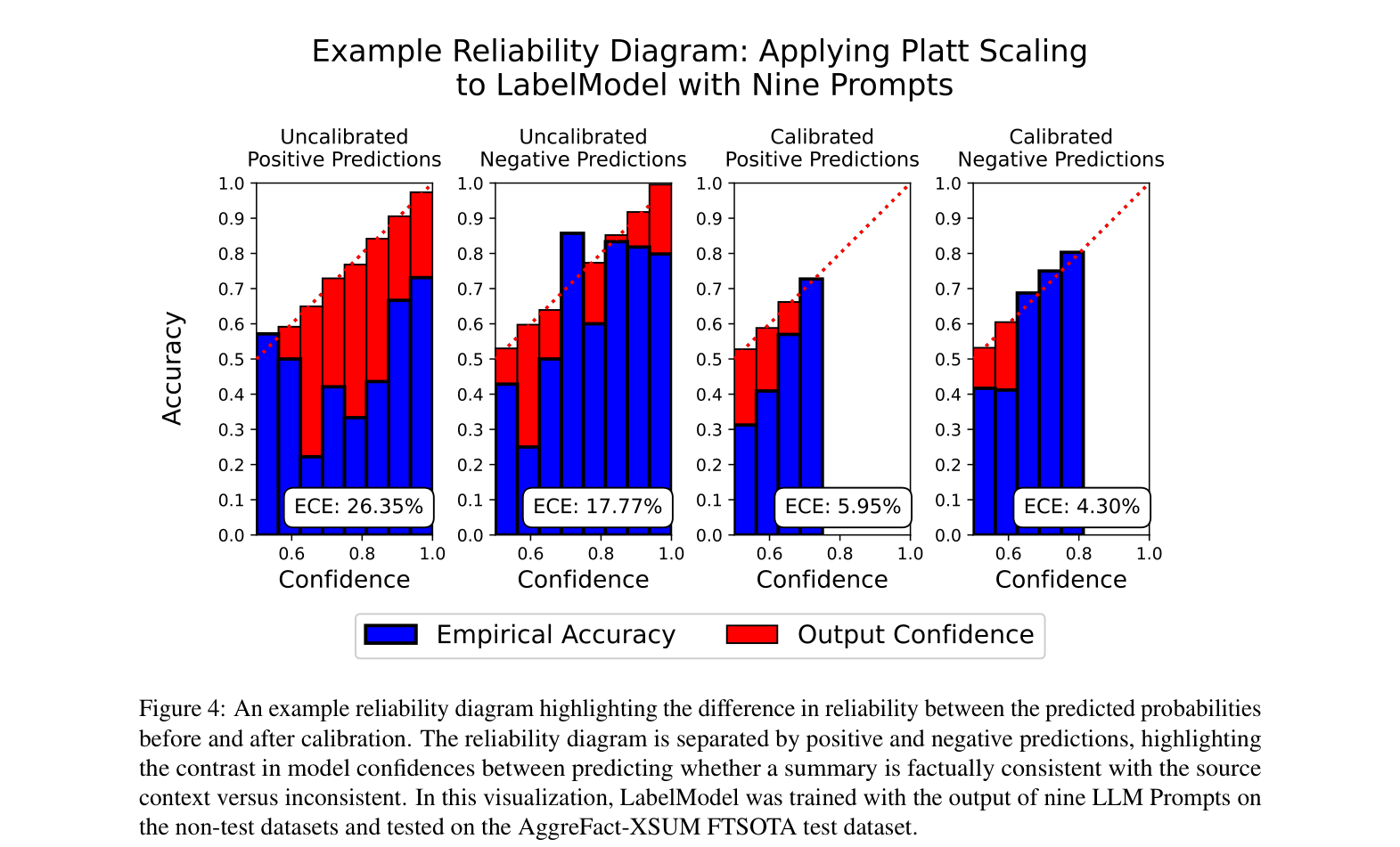
- Calibrate the final probability output to ensure the reported confidence matches empirical accuracy
Architecture
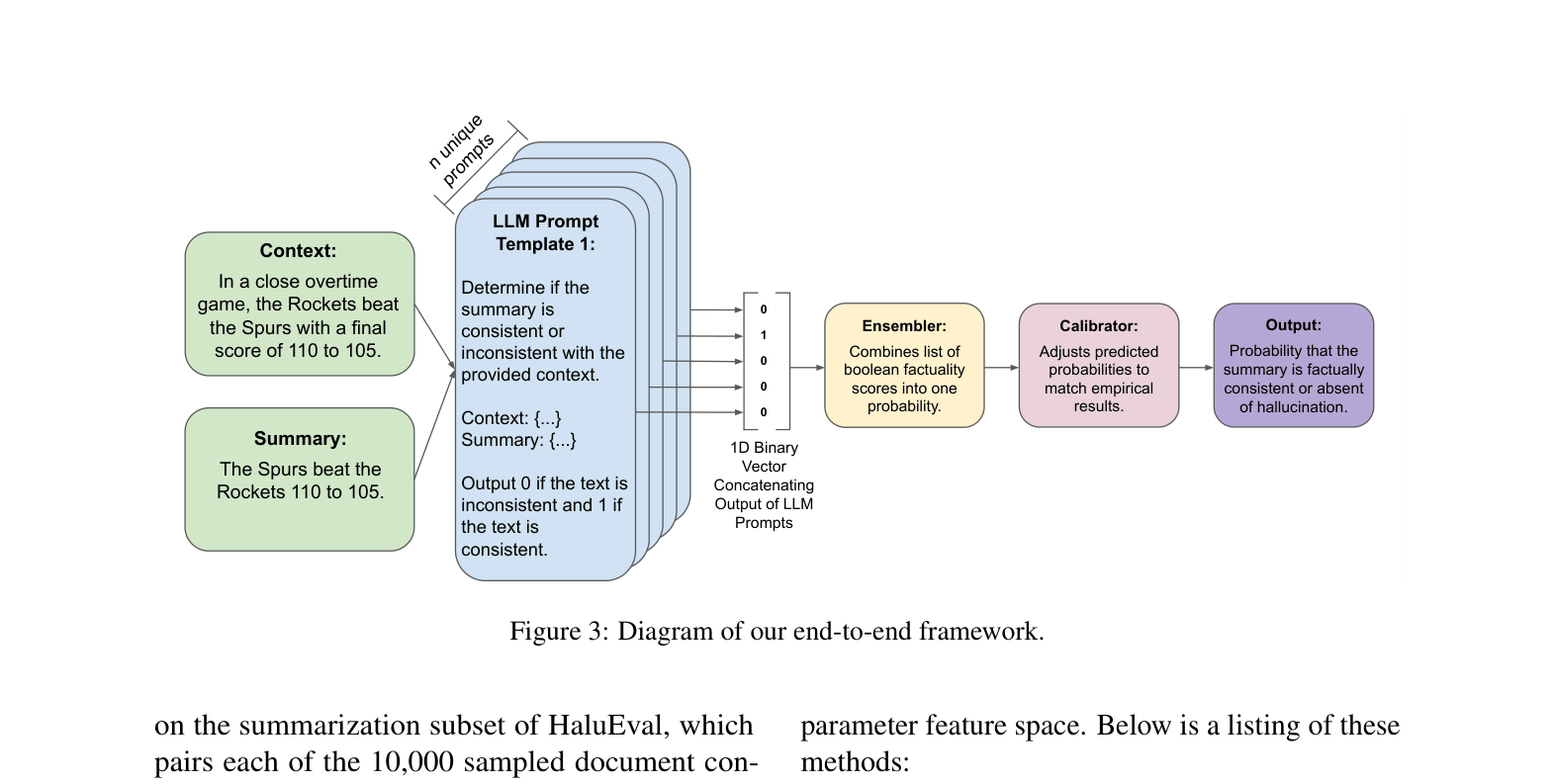
The complete DEEP framework pipeline: Prompts -> Binary Features -> Ensembler -> Calibrator
Evaluation Highlights
- Achieves State-of-the-Art balanced accuracy on AggreFact-XSUM FTSOTA (71.9%), TofuEval Summary-Level (79.4%), and HaluEval Summarization (74.1%)
- Ensembling just 3 prompts consistently yields performance improvements over the single best individual prompt across all datasets
- Calibration using Platt Scaling reduces Expected Calibration Error (ECE) to under 6% for top models, significantly mitigating overconfidence
Breakthrough Assessment
8/10
Significantly outperforms encoder-based baselines in realistic settings (no test-set thresholding) and demonstrates that ensembling LLM prompts is a viable, superior alternative to fine-tuning for factuality detection.