📊 Experiments & Results
Evaluation Setup
Question Answering on 8,920 atomic legal facts derived from Wikidata
Benchmarks:
- LexFact (Proposed) (Legal Knowledge Probing (QA)) [New]
Metrics:
- Precision (P = Correct / Answered)
- Recall (R = Correct / Total Questions)
- Abstain Rate
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Impact of evaluation metrics: Fuzzy Matching (FM) significantly reveals more knowledge than Exact Match (EM). | ||||
| LexFact | Precision (SaulLM, Few-shot + Abstain) | 36 | 81 | +45 |
| LexFact | Precision (Mistral-7B, Few-shot + Abstain) | 8 | 63 | +55 |
| Impact of Domain-Specific Training: SaulLM (Legal-trained) vs Mistral (Base). | ||||
| LexFact | Precision (Fuzzy Match) | 63 | 81 | +18 |
| Impact of Prompting Strategy: Few-shot examples improve precision. | ||||
| LexFact | Precision Improvement | Not reported as single aggregate | Not reported as single aggregate | Positive |
Experiment Figures
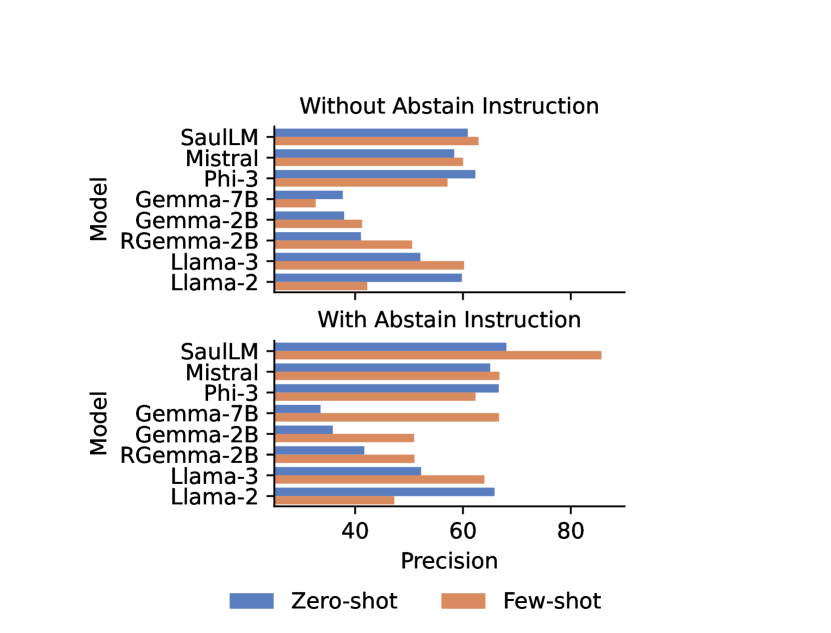
Precision scores of 8 models under 4 settings: Zero-shot/Few-shot crossed with Forced-Answer/Abstain-Allowed.
Main Takeaways
- Exact matching drastically underestimates LLM knowledge; Alias and Fuzzy matching are essential for realistic evaluation of verbose models.
- Abstention instructions ('answer I don't know') successfully increase precision across most models, though at the cost of recall.
- Domain-specific pre-training (SaulLM) yields the highest factual precision (81%), significantly outperforming general-purpose models like Llama-3 and Mistral.
- Few-shot prompting corrects systematic formatting errors (e.g., case title structure) and aligns output types (e.g., answering 'USA' instead of state names for jurisdiction).