📝 Paper Summary
Factual Knowledge in LLMs
Knowledge Externalization
Modularized RAG pipeline
LmLm (Limited Memory Language Models) modify the pre-training process to mask factual values from the loss, forcing the model to learn database lookup calls rather than memorizing facts in weights.
Core Problem
Standard LLM pre-training entangles linguistic competency with factual knowledge in neural weights, making it difficult to update specific facts, unlearn sensitive data, or verify information sources.
Why it matters:
- Factual errors (hallucinations) are hard to fix because knowledge is distributed across billions of opaque parameters
- Removing outdated or inappropriate knowledge (machine unlearning) typically degrades general model utility or fails to fully erase the data
- Reliable memorization requires observing facts many times during training, which is inefficient for long-tail knowledge
Concrete Example:
A customer service agent for a restaurant chain should not answer questions about real estate law, but standard LLMs cannot easily isolate or remove this training data. Furthermore, traditional RAG models often fall back on internal (potentially hallucinatory) knowledge when retrieval fails.
Key Novelty
Pre-training with Factual Masking
- Annotates the pre-training corpus with explicit database lookup calls for entity-level facts (triplets)
- During pre-training, the model is trained to generate the lookup call, but the actual factual values (the answer) are masked from the loss calculation
- This forces the model to rely on external retrieval rather than memorization, effectively 'hollowing out' the parametric memory of facts
Architecture
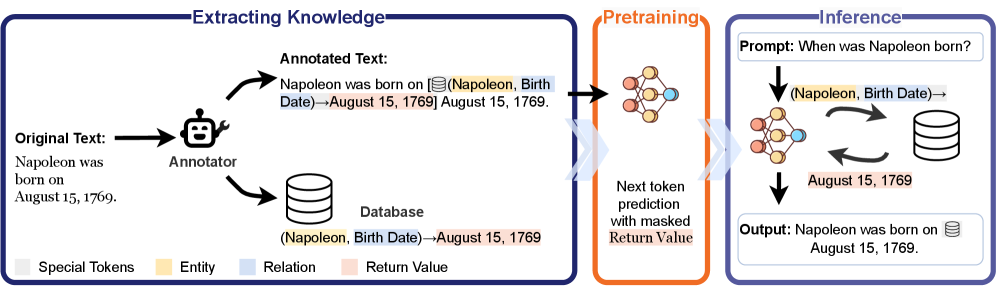
Overview of the LmLm pre-training process compared to standard pre-training. Shows how facts are extracted to a database and replaced with lookup calls in the training data.
Evaluation Highlights
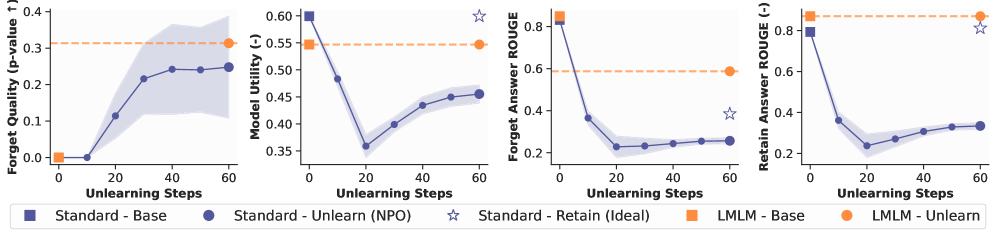
- LmLm (382M parameters) matches the factual precision of LLaMA2-7B on benchmarks, despite being ~18x smaller
- Achieves instant, perfect unlearning on the TOFU benchmark without degrading model utility (Retain Set performance), unlike gradient-based methods
- Reduces perplexity by ~1.98 points (Dynamic setting) compared to standard models of the same size, indicating learning to look up is more efficient than memorizing
Breakthrough Assessment
8/10
Offers a fundamental shift in pre-training objectives by explicitly discouraging memorization. Solves the unlearning problem structurally rather than algorithmically.