📝 Paper Summary
Hallucination detection
Factuality evaluation
RLHF / Preference optimization
FenCE is a fine-grained evaluator trained on public datasets augmented with tool-retrieved documents and textual critiques, which is then used to align generators to be more factual via critique-based revision and preference optimization.
Core Problem
Existing factuality evaluators rely on restricted sources (e.g., Wikipedia only) and output opaque binary scores, while generator training often forces models to hallucinate lesser-known facts they haven't memorized.
Why it matters:
- Hallucination remains a persistent issue where LLMs blur the line between memorized facts and plausible-sounding errors
- Current evaluator training data lacks diversity in evidence sources and interpretability in feedback
- Standard preference training can hurt factuality by reinforcing the generation of obscure facts the model does not actually know
Concrete Example:
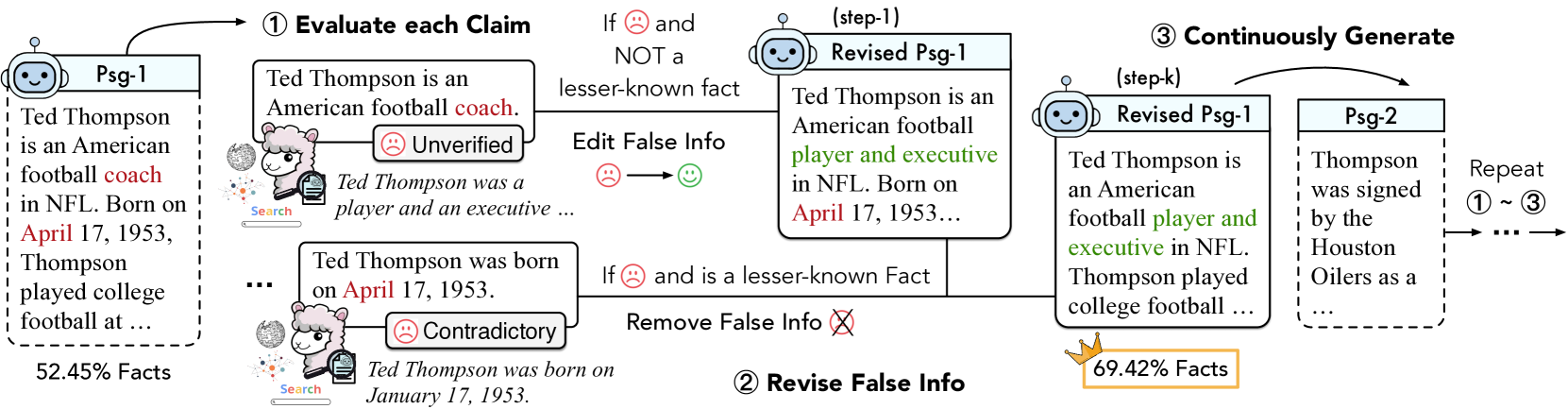
When a generator claims something incorrect about a specific news event, a standard evaluator might just output '0.2 score' based on a single Wikipedia snippet. FenCE retrieves diverse news articles, generates a critique explaining *why* it's wrong (e.g., 'contradicted by CNN report'), and guides the generator to remove the claim if it's unknown to the model.
Key Novelty
Fine-grained Critique-based Evaluator (FenCE)
- Augments public factuality datasets by using tools (Search, Knowledge Graph) to find diverse evidence and prompting strong LLMs to generate explanatory textual critiques alongside labels
- Improves generator factuality by using FenCE to critique and revise responses, specifically filtering out 'unknown' facts to prevent forcing the model to hallucinate unmemorized information
- Uses FenCE to score both original and revised responses to create preference pairs for DPO (Direct Preference Optimization) training
Architecture
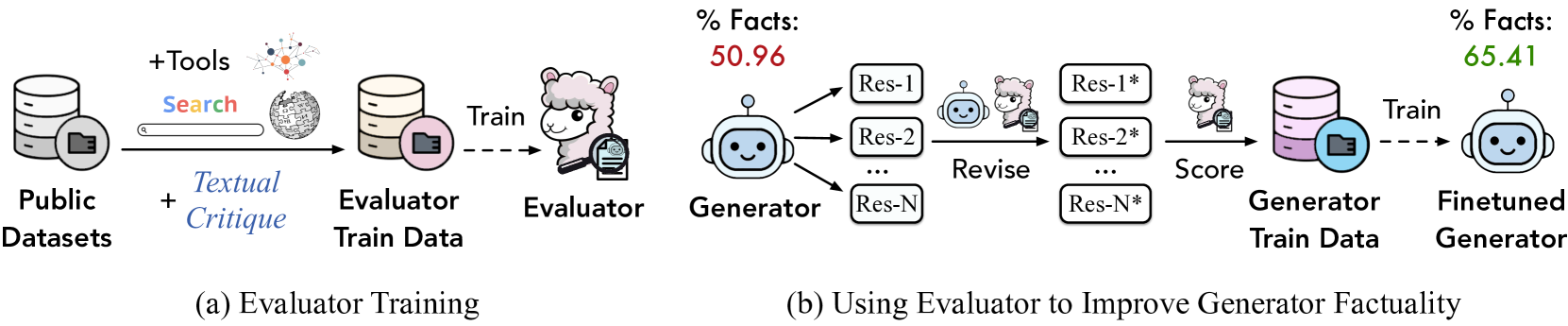
Overview of the FenCE framework, split into (a) Evaluator Training and (b) Generator Training.
Evaluation Highlights
- FenCE improves Llama-3-8B-Instruct's balanced accuracy on the LLM-AggreFact benchmark by 8.3%, outperforming significantly larger models like Mistral-Large-123B and Claude-3 Opus
- Finely-tuning Llama2-7B-chat with FenCE feedback increases its FActScore factuality rate by 16.86%, surpassing state-of-the-art methods like R-Tuning and PO-SO
- On TruthfulQA, the FenCE-trained generator improves by 17.64% relative to the base model, outperforming existing baselines by 3.99%
Breakthrough Assessment
8/10
Strong methodological contribution in data augmentation for evaluators and a sensible training recipe that avoids 'hallucination reinforcement' by filtering unknown facts. Results significantly outperform larger proprietary models.