📝 Paper Summary
Knowledge internalization
Hallucination suppression
LLMs encode significantly more factual knowledge in their internal representations than they express in their generated outputs, sometimes perfectly knowing answers they fail to generate even once.
Core Problem
It is unclear whether LLMs store more factual information than they express, and relying on generated outputs (external knowledge) may underestimate the model's true capabilities.
Why it matters:
- Undisclosed knowledge poses safety risks if sensitive information surfaces unexpectedly
- Knowing that models possess unused knowledge suggests performance could be improved by surfacing it rather than retraining
- Current evaluation methods based on single generated answers fail to distinguish between lack of knowledge and failure to retrieve it
Concrete Example:
A model asked 'Which company is Volvo B58 produced by?' fails to generate the correct answer ('Volvo Buses') in 1,000 attempts, yet an internal probe correctly ranks 'Volvo Buses' higher than the incorrect generated answer 'BMW Group'.
Key Novelty
Formal framework for 'Hidden Knowledge'
- Defines knowledge as the ability to rank correct answer candidates higher than incorrect ones across all pairs
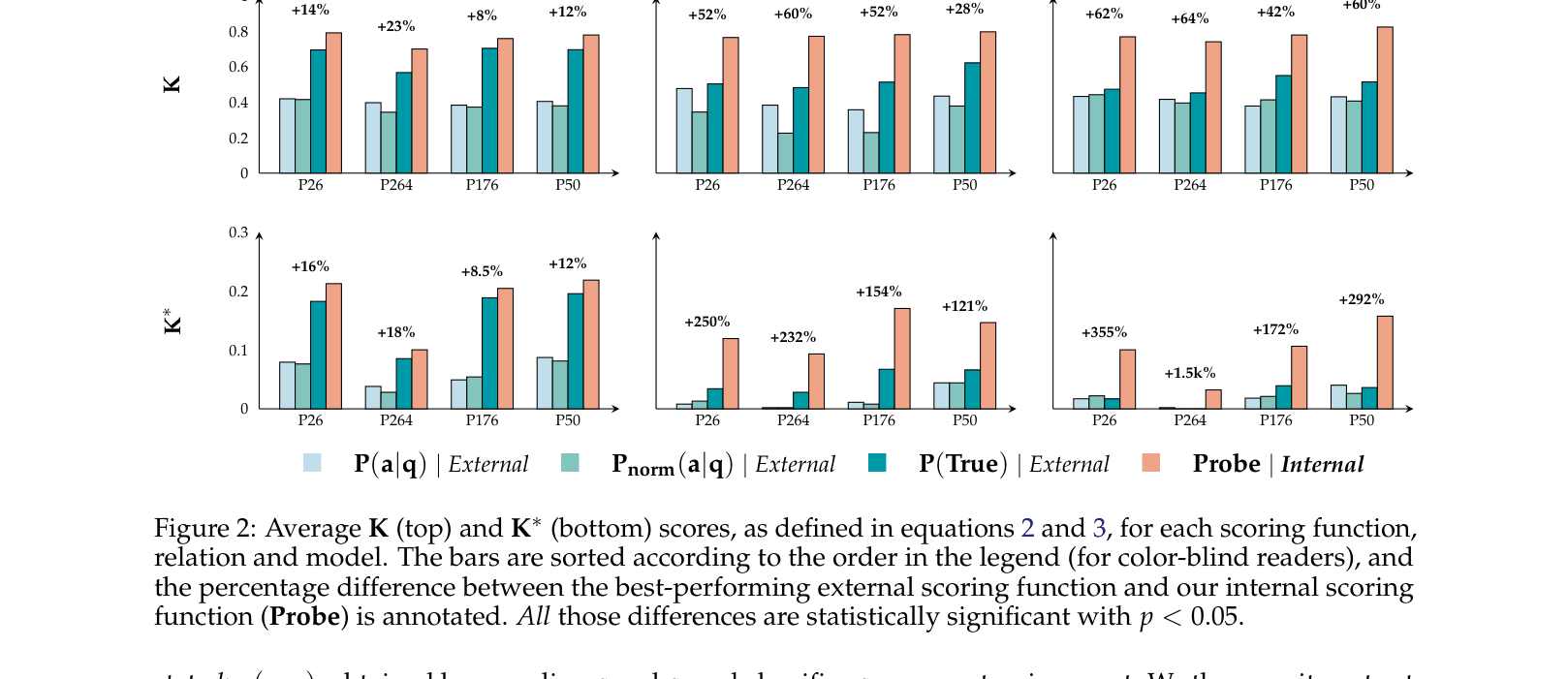
- Distinguishes between 'external knowledge' (ranking via token probabilities) and 'internal knowledge' (ranking via probing classifiers on hidden states)
- Quantifies 'hidden knowledge' as the gap where internal ranking accuracy significantly exceeds external ranking accuracy
Architecture

The conceptual framework for measuring hidden knowledge via pairwise ranking.
Evaluation Highlights
- Internal knowledge scores consistently exceed external scores across Llama-3, Mistral, and Gemma-2, with an average relative gap of 40%
- In 9% of questions, models perfectly know the correct answer (internal ranking is perfect) despite failing to generate it even once in 1,000 samples
- Using internal probes to select from sampled answers improves QA accuracy by 12% over greedy decoding, with potential for 52% improvement if generation constraints were removed
Breakthrough Assessment
8/10
Provides the first formal definition and quantification of hidden knowledge, revealing a fundamental 'tip-of-the-tongue' limitation in LLM generation capabilities.