📝 Paper Summary
Factual Consistency Evaluation
Benchmark Creation
Most LLMs struggle with factual reasoning and detecting inconsistencies in summaries when tested on a new, high-quality 10-domain benchmark (SUMM EDITS) created via a reproducible protocol.
Core Problem
Existing benchmarks for factual consistency are often plagued by low label reliability and simplicity, while LLMs that appear accurate often fail to correctly explain their reasoning or detect subtle errors.
Why it matters:
- Unreliable benchmarks prevent accurate measurement of model progress, with manual analysis revealing 6%+ mislabeled samples in popular datasets like AggreFact
- Trusting LLMs for critical tasks (like summarizing medical records) requires them to not just classify correctly but to reason correctly about facts, which current metrics often fail to capture
- Crowd-sourced annotations often lack reproducibility (low inter-annotator agreement), making it hard to distinguish model failure from label noise
Concrete Example:
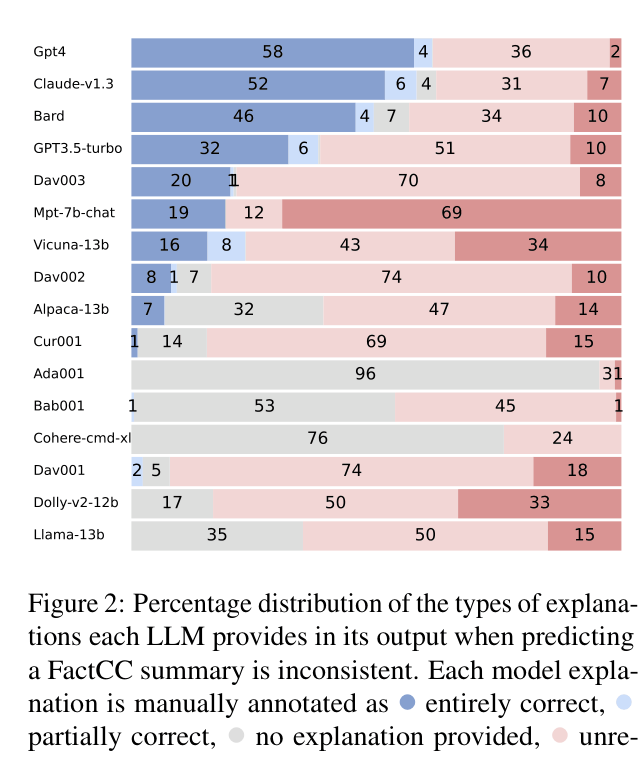
In the AggreFact benchmark, GPT-4 correctly identified inconsistencies in 101 summaries that were labeled 'consistent' by the dataset creators, proving the dataset itself was flawed. Conversely, models like LLaMA-13B might guess the right binary label ('inconsistent') but provide unrelated justifications (e.g., complaining about the summary format rather than the facts).
Key Novelty
SUMM EDITS Protocol & Benchmark
- A 3-step protocol: Verify a seed summary, generate many atomic edits (using LLMs) that introduce specific errors, and have a human verify only the edits, ensuring high efficiency and reproducibility
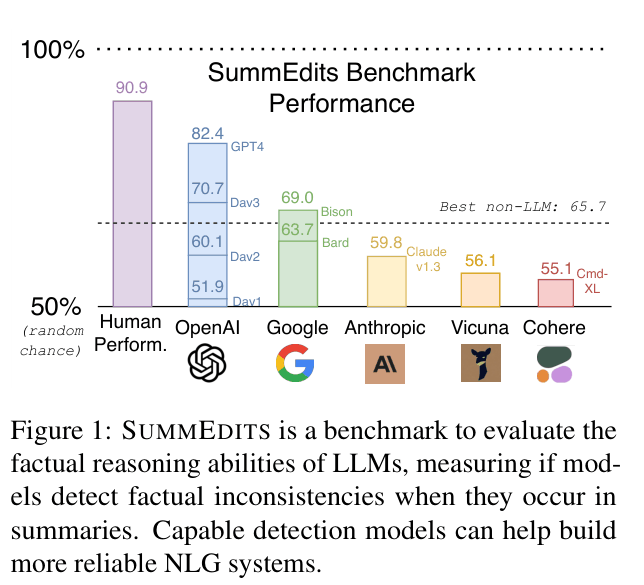
- Creation of SUMM EDITS: A 10-domain benchmark (Sales, Legal, News, etc.) where models must detect inconsistencies in minimal edits, estimating human performance at ~91% while models lag behind
Architecture
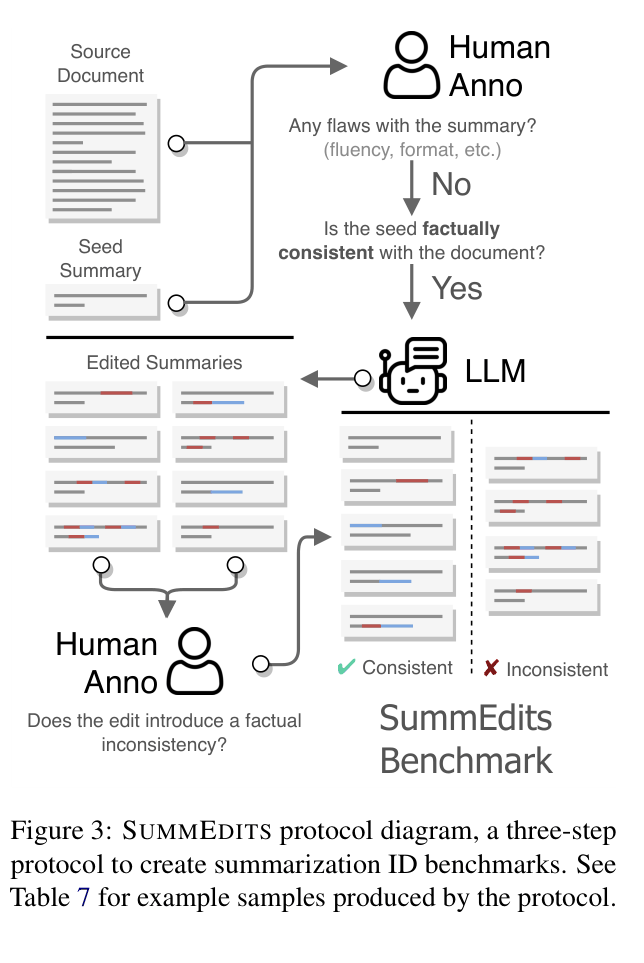
The 3-step SUMM EDITS protocol for creating consistent benchmarks
Evaluation Highlights
- GPT-4 achieves 82.4% balanced accuracy on SUMM EDITS, outperforming the best specialized non-LLM (QAFactEval at 65.7%) but still trailing human performance (90.9%)
- Most open-source LLMs perform near random chance (e.g., LLaMA-13B at 50-52%) on standard benchmarks when analyzed for reasoning, not just binary accuracy
- Inter-annotator agreement on SUMM EDITS is ~0.92 (Cohen's Kappa), significantly higher than prior benchmarks like DialSummEval (0.67)
Breakthrough Assessment
9/10
Establishes a new standard for factual consistency benchmarks with extremely high reproducibility. Exposes the 'reasoning gap' in LLMs that previous metrics masked.