📝 Paper Summary
Factuality evaluation
Hallucination suppression
FACTOR automatically transforms factual corpora into multiple-choice benchmarks where LMs must distinguish true completions from similar but non-factual perturbations, measuring propensity for factual generation.
Core Problem
Existing factuality evaluations rely on sampling from the LM itself (over-representing common facts) or perplexity (a noisy proxy affected by style), failing to measure accuracy on a controlled set of domain-specific facts.
Why it matters:
- LMs frequently generate factually incorrect information, hindering deployment in sensitive domains
- Current sampling-based metrics bias evaluation toward high-likelihood facts, ignoring the 'long-tail' of rare facts
- Perplexity is influenced by linguistic phenomena other than factuality and does not always correlate with factual correctness
Concrete Example:
A model might complete 'Steve Jobs left Apple in...' correctly with '1985' but assign high likelihood to plausible errors like '1988' or 'forced out of NeXT'. FACTOR tests if the true fact (1985) is ranked higher than these specific, generated contradictions.
Key Novelty
Factual Assessment via Corpus TransfORmation (FACTOR)
- Automatically transforms a text corpus into a benchmark by using a helper LLM (InstructGPT) to generate non-factual, fluent, and similar contradictions for specific sentences
- Evaluates models based on their ability to assign higher likelihood to the original true sentence compared to the generated non-factual alternatives
- Categorizes errors into specific types (Entity, Predicate, Circumstance, etc.) to ensure diversity in the non-factual distractors
Architecture
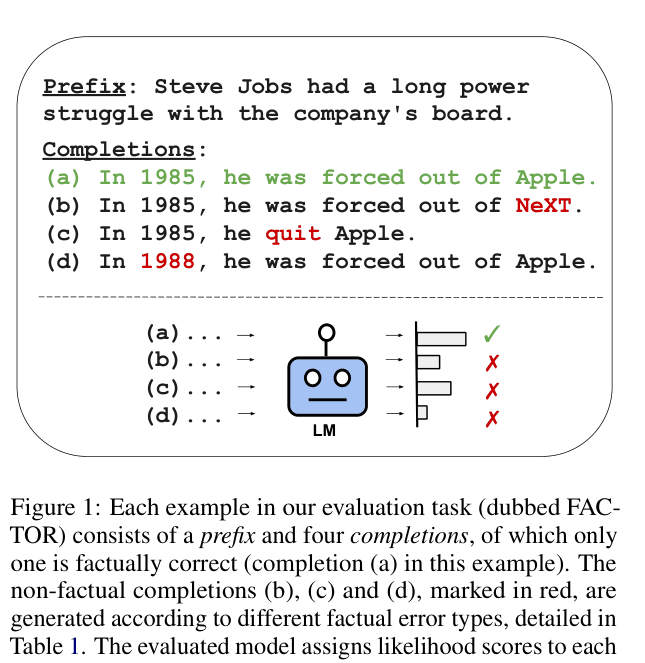
Conceptual overview of the FACTOR evaluation task
Evaluation Highlights
- Larger models perform better but still struggle: OPT-66B achieves only 68.1% on News-FACTOR and 55.9% on Expert-FACTOR
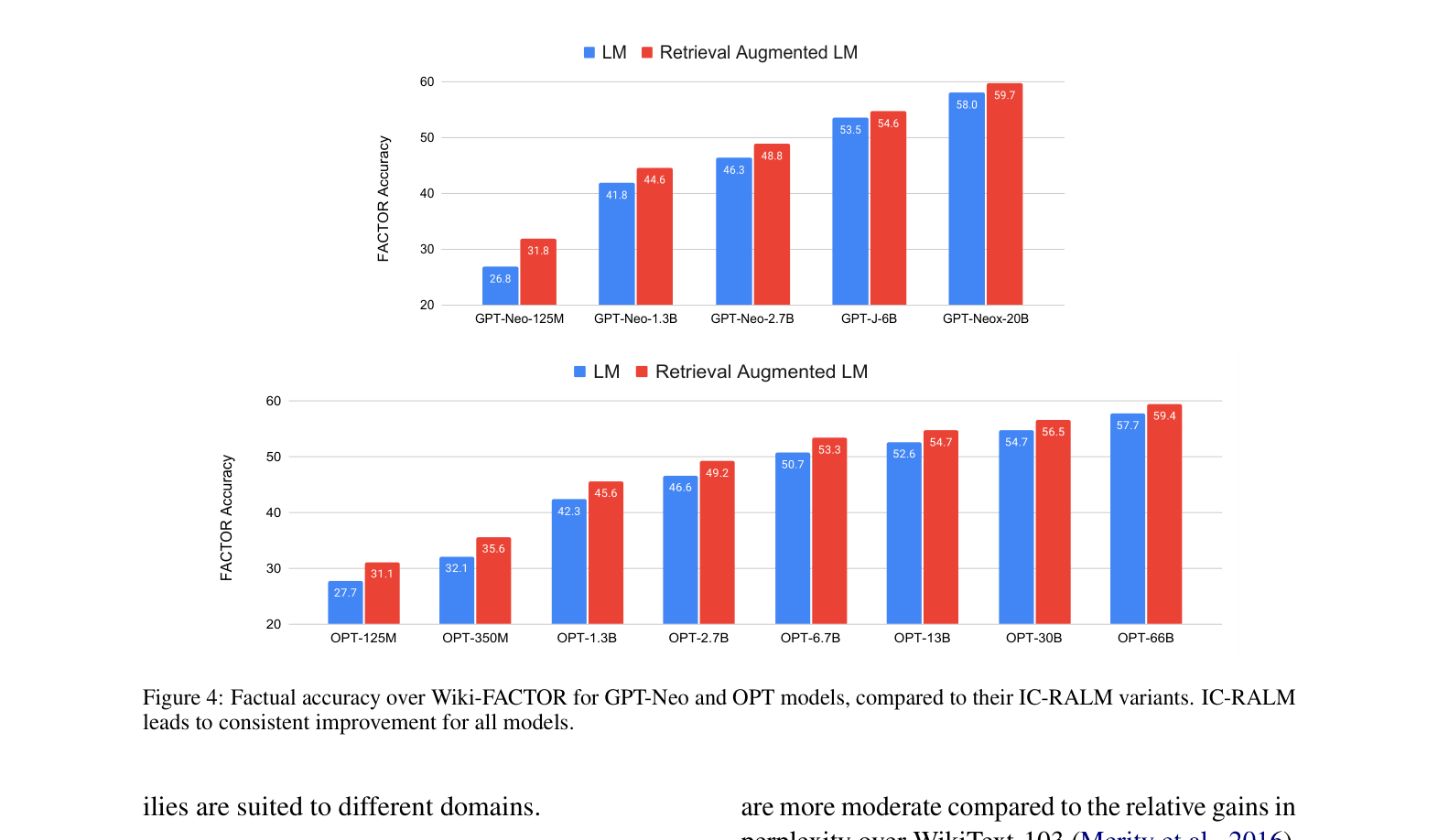
- Retrieval augmentation (IC-RALM) consistently improves FACTOR scores across all model sizes (e.g., GPT-Neo-2.7B improves from ~46% to ~50% on Wiki-FACTOR)
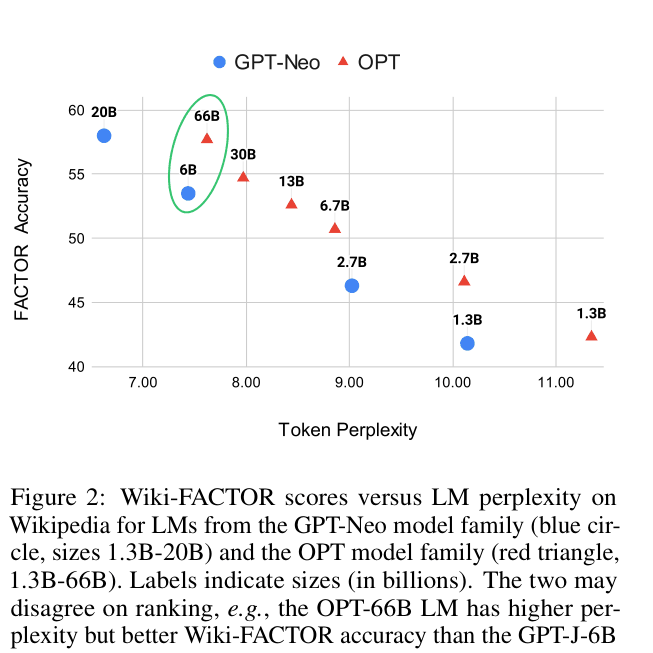
- FACTOR ranking diverges from perplexity: OPT-66B has higher perplexity (worse) than GPT-J-6B (7.6 vs 7.4) but significantly better FACTOR accuracy (57.7% vs 53.5%)
Breakthrough Assessment
8/10
A novel, scalable methodology for creating controlled factuality benchmarks without human labeling. It exposes discrepancies between perplexity and factuality, offering a more precise metric for knowledge-intensive tasks.