📝 Paper Summary
Medical Text Simplification
Factuality Evaluation
FACTPICO is an expert-annotated benchmark for evaluating the factuality of LLM-generated plain language summaries of medical evidence, specifically focusing on critical trial elements (Populations, Interventions, Comparators, Outcomes) and analyzing automated metric performance.
Core Problem
Plain language summarization of medical evidence by LLMs lacks a standard evaluation benchmark, making it unknown whether current models introduce critical factual errors in high-stakes domains.
Why it matters:
- RCT abstracts are inaccessible to laypeople, preventing patients from accessing up-to-date healthcare evidence
- LLM-generated simplifications risk introducing health-critical errors if not rigorously fact-checked
- Existing factuality metrics correlate poorly with expert judgments on granular medical details, rendering automated evaluation unreliable
Concrete Example:
In a study about genetic risk and folate intake, GPT-4 correctly identified the intervention (personalized advice) but completely omitted the comparator (general healthy eating advice), making it impossible for a reader to understand what the intervention was tested against. This omission distorts the trial's actual findings.
Key Novelty
Fine-Grained Expert Evaluation of RCT Elements (FACTPICO)
- Decomposes evaluation into specific PICO elements (Population, Intervention, Comparator, Outcome) and Evidence Inference rather than a single generic quality score
- Includes expert-written natural language rationales for every rating, documenting the reasoning behind factuality judgments and addressing the correctness of added explanations
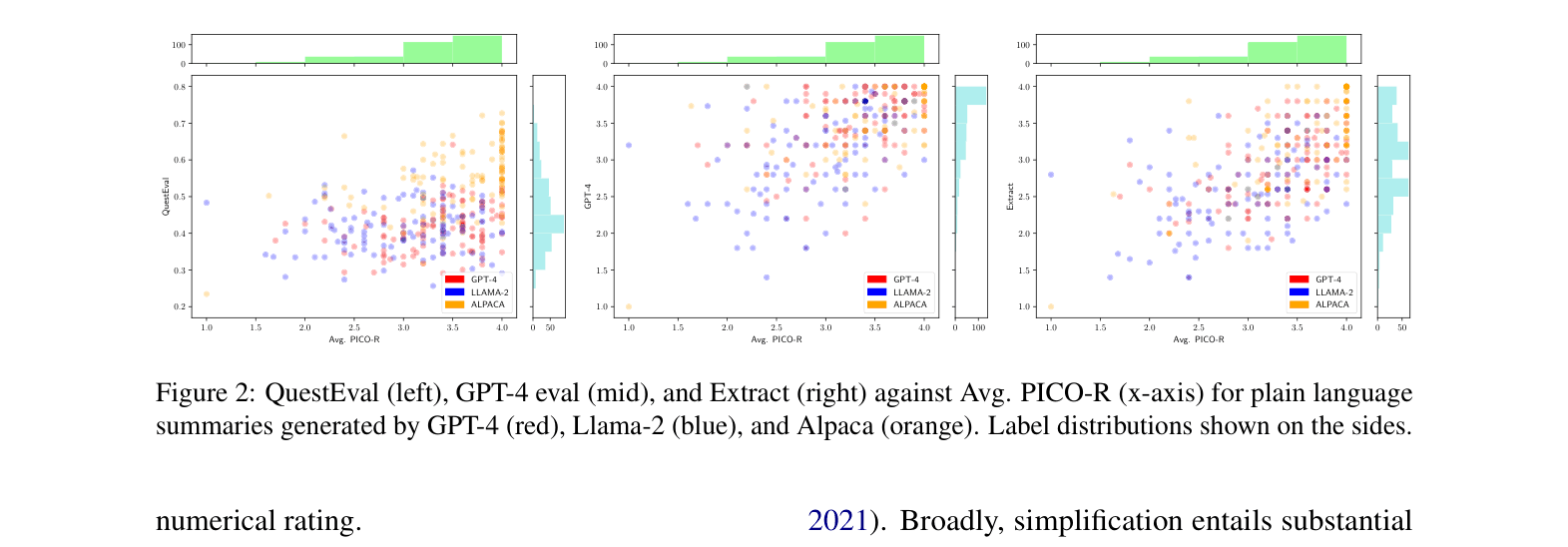
- Proposes a PICO-R extraction pipeline that first isolates key medical elements before evaluating them, significantly improving LLM-based evaluator performance
Architecture

An example of the FACTPICO annotation interface and process, showing a GPT-4 generated summary and the corresponding expert evaluation of PICO elements
Evaluation Highlights
- PICO-R extraction pipeline (GPT-4) achieves highest correlation with experts (Kendall's τb = 0.475), outperforming standard GPT-4 evaluation (0.055)
- LLM simplifications frequently contain non-factual additions (hallucinations): 31.3% of GPT-4 summaries and 38.3% of Llama-2 summaries contain at least one non-factual added span
- Existing automatic metrics (e.g., QuestEval, DAE) show weak to moderate correlation with human judgment (Spearman's ρ ranging from 0.219 to 0.412), failing to capture instance-level nuance
Breakthrough Assessment
8/10
Creates a critical, high-quality expert benchmark for a high-stakes domain. Reveals significant flaws in both LLM summarizers and current evaluation metrics, establishing a new standard for medical text simplification evaluation.