📊 Experiments & Results
Evaluation Setup
Zero-shot QA on time-sensitive facts using the DyKnow framework.
Benchmarks:
- DyKnow (Dynamic Factual QA) [New]
Metrics:
- Accuracy (Correct vs Outdated vs Irrelevant)
- Prompt Agreement (Consistency under Subject/Property perturbation)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Assessment of State-of-the-Art LLMs on DyKnow Benchmark showing prevalence of outdated knowledge. | ||||
| DyKnow | Correctness | 80 | 58 | -22 |
| DyKnow | Prompt Agreement (Subject Perturbation) | 15 | 75 | +60 |
Experiment Figures
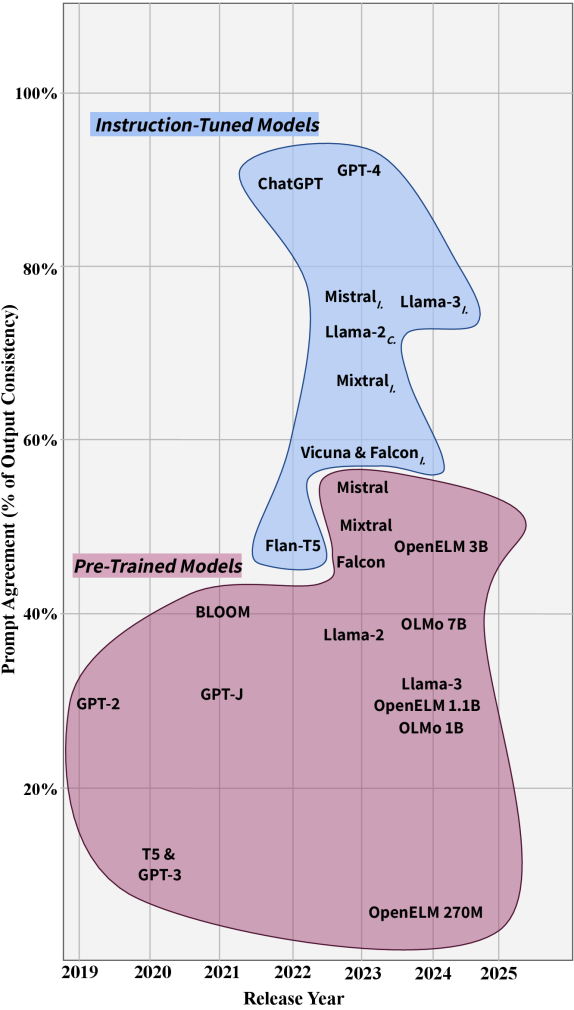
Prompt agreement levels (consistency) of 24 LLMs under Subject Perturbations.
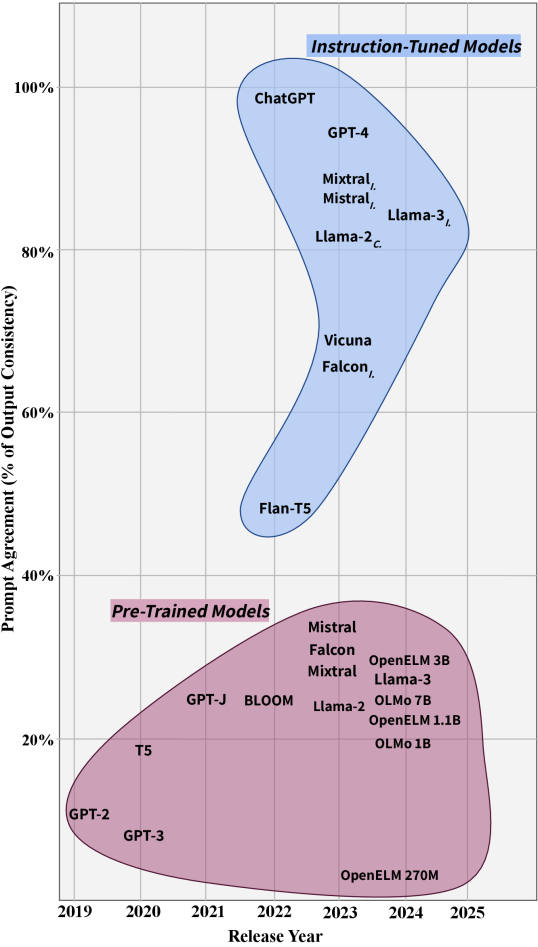
Prompt agreement levels of 24 LLMs under Property Perturbations.
Main Takeaways
- All evaluated LLMs (including GPT-4 and Llama-3) exhibit significant ratios of outdated knowledge (20-40%).
- Instruction-tuned models show higher consistency (Prompt Agreement) than their base model counterparts.
- RAG outperforms Knowledge Editing methods (ROME, MEMIT) in providing accurate, up-to-date answers.
- Entity-Aware Fine-tuning (ENAF) enhances consistency by grounding diverse surface forms of an entity to a single symbolic representation.