📝 Paper Summary
Factuality Evaluation
LLM Benchmarking
FELM is a benchmark for evaluating LLM factuality across five domains using fine-grained segment-level annotations, error types, and reference links to gauge the reliability of factuality evaluators.
Core Problem
Existing factuality benchmarks focus narrowly on world knowledge or specific tasks like summarization, often using text from weaker models, which fails to capture the diverse hallucination patterns of modern LLMs.
Why it matters:
- LLMs like ChatGPT are widely used for diverse tasks (math, coding, reasoning) beyond simple fact retrieval, yet they still hallucinate significantly.
- Without reliable 'meta-evaluation' benchmarks (evaluating the evaluators), it is impossible to gauge progress in developing automated factuality detection systems.
- Current factuality metrics often lack granularity, making it difficult for users to pinpoint exactly which part of a long response is incorrect.
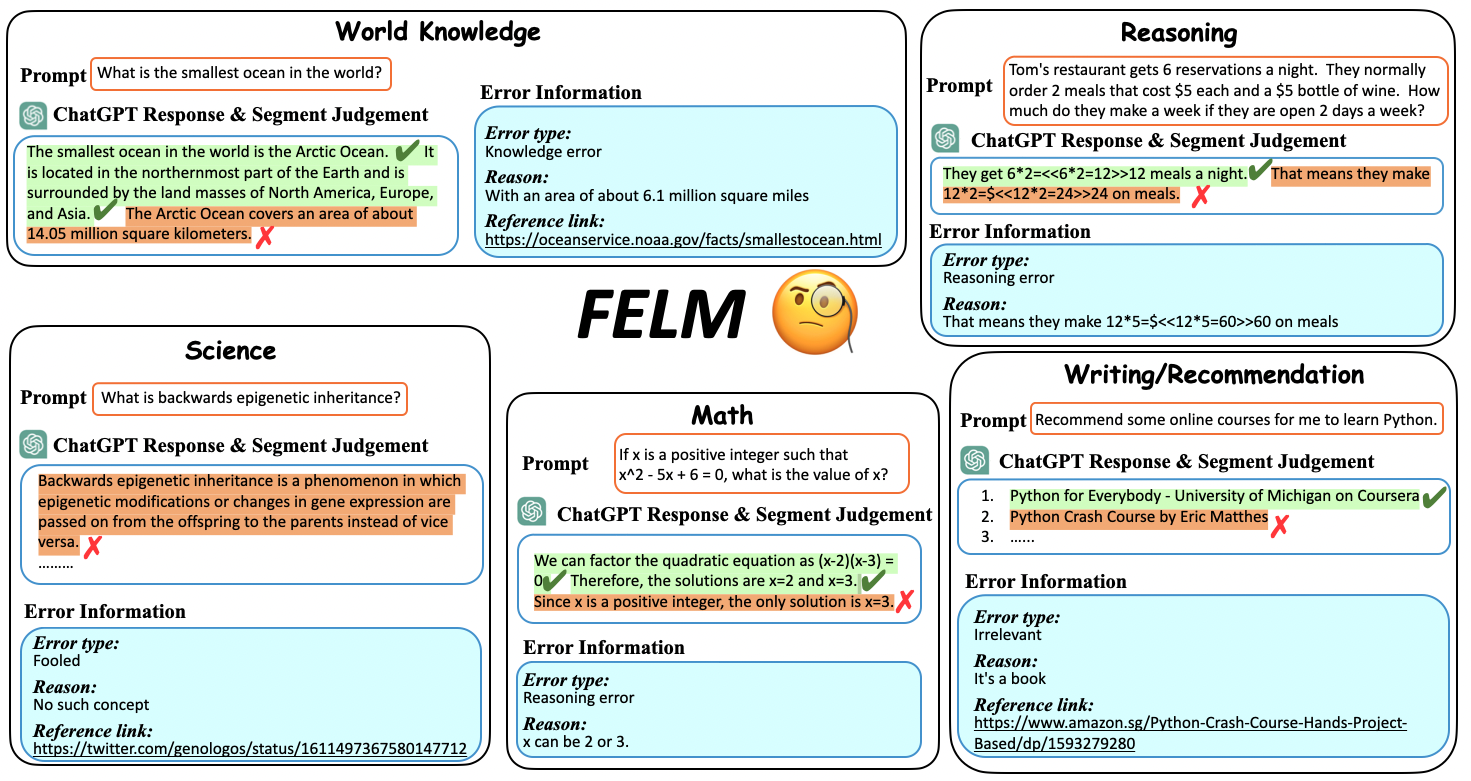
Concrete Example:
A prompt asking 'Is it true that new year's day 2023 falls on a Friday the 13th?' might trigger ChatGPT to agree ('Yes, it is true...'). Current evaluators might miss this 'Fooled error' or fail to identify the specific incorrect segment within a long response.
Key Novelty
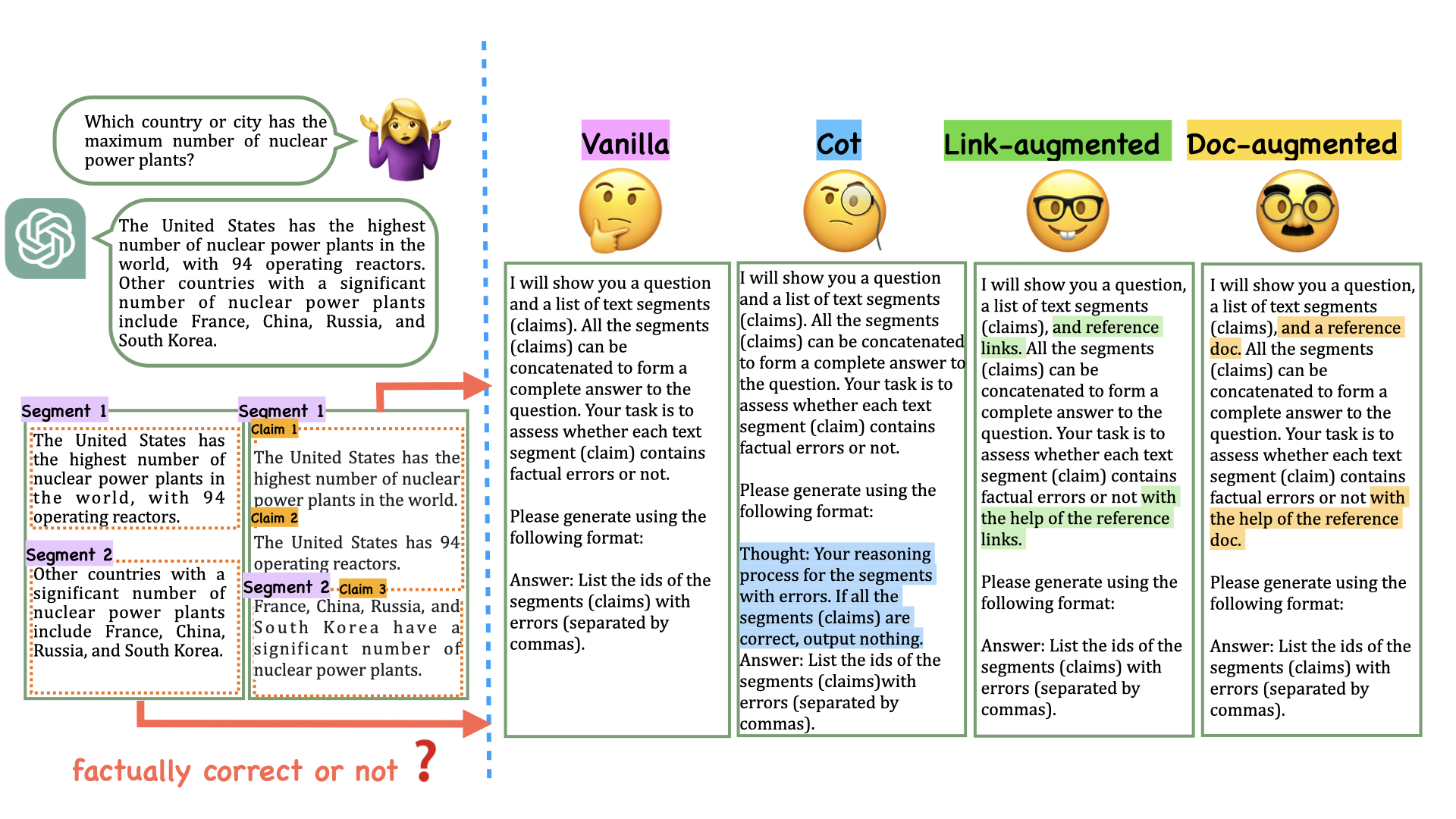
Multi-Domain Segment-Level Factuality Benchmark
- Broadens factuality to five domains (World Knowledge, Science/Tech, Math, Reasoning, Writing/Rec) to match LLM capabilities, rather than just Wikipedia-based knowledge.
- Uses segment-level granularity (splitting responses into self-contained text spans) for precise error localization, unlike whole-response labels.
- Provides rich meta-data for every error: specific error type (e.g., Knowledge error, Reasoning error), error reasoning, and URL references supporting the judgment.
Architecture
Data scheme of FELM showing the annotation process and structure.
Evaluation Highlights
- The overall factual error rate of ChatGPT on FELM is 31.8% at the response level.
- Human annotators achieve a high segment-level agreement rate of 90.7% on average.
- Current LLMs (ChatGPT and GPT-4) struggle as evaluators; findings show they are far from satisfactory in faithfully detecting factual errors.
Breakthrough Assessment
8/10
Significantly expands the scope of factuality evaluation beyond standard Wikipedia/summarization tasks to include reasoning and math, with high-quality expert annotation.