📝 Paper Summary
Hallucination suppression
Alignment without Reinforcement Learning
FactAlign improves the factual accuracy of long-form responses by aligning models using fine-grained, sentence-level signals from an automatic factuality evaluator rather than just binary response-level feedback.
Core Problem
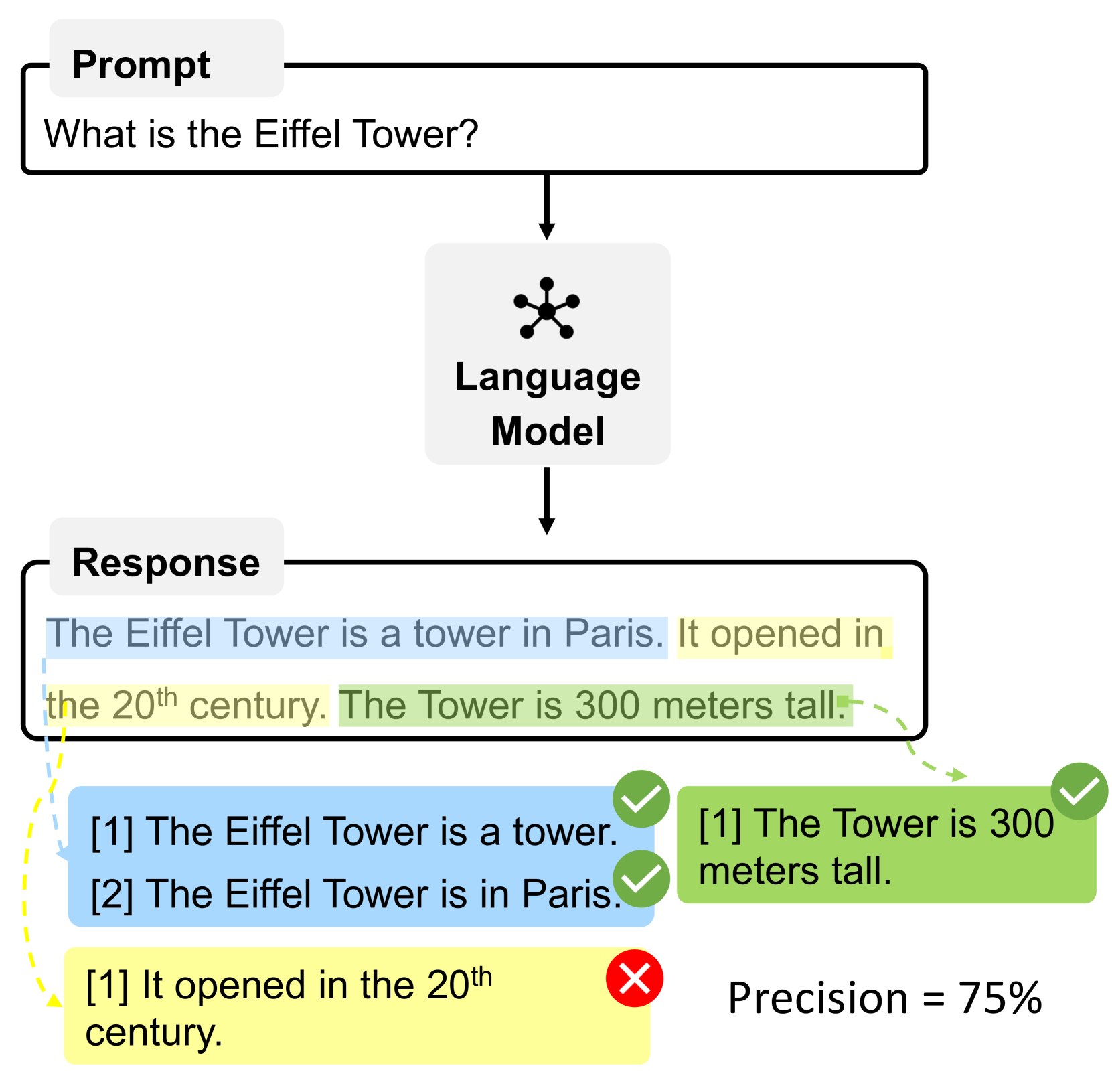
LLMs frequently hallucinate in long-form responses, and standard alignment methods (like RLHF or DPO) typically use coarse-grained response-level signals that fail to capture specific factual errors within a long text.
Why it matters:
- Long-form generation makes factuality assessment complex, as a response can be partially correct and partially hallucinated
- Current alignment methods often sacrifice helpfulness to improve factuality, or vice versa (the alignment tax)
- Reliability is a crucial requirement for real-world adoption, but quantifying and improving long-form factuality remains non-trivial
Concrete Example:
In a long biography of a scientist, a model might get the birth date right but hallucinate the university they attended. A standard response-level reward might label the whole response 'bad' (losing good info) or 'good' (reinforcing the hallucination), whereas FactAlign identifies and targets specifically the sentence containing the wrong university.
Key Novelty
FactAlign with fKTO (fine-grained Kahneman-Tversky Optimization)
- Extends the KTO alignment algorithm to operate at the sentence level (fKTO), treating each sentence as a mini-completion to be optimized based on its individual factual precision
- Combines this fine-grained objective with a response-level objective to balance factual precision with overall helpfulness and recall
- Utilizes an iterative self-training loop where the model generates responses, an automatic evaluator scores them, and the model is re-aligned on its own high-quality outputs
Architecture
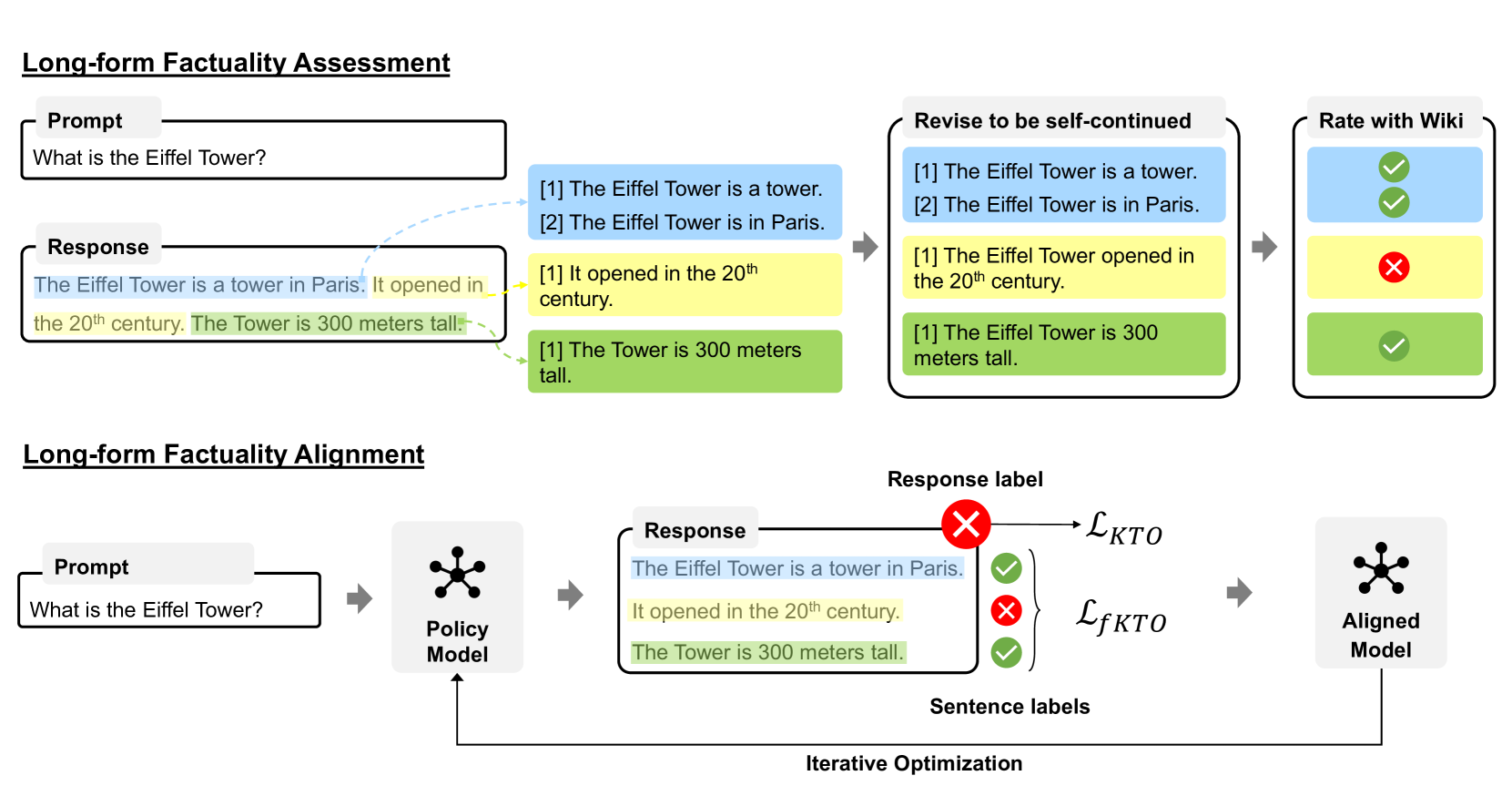
The FactAlign framework workflow, illustrating the generation, evaluation, and multi-granularity alignment process.
Evaluation Highlights
- +13.5% improvement in Factual F1 score on the LongFact-Concepts benchmark compared to the base model (Llama-3-8B-Instruct)
- Outperforms standard DPO and KTO baselines on factual precision while maintaining or improving helpfulness (win-rate against base model)
- Achieves superior factuality-helpfulness trade-offs compared to FactTune and other alignment baselines across open-domain and information-seeking tasks
Breakthrough Assessment
7/10
Solid methodology extending KTO to fine-grained signals. While it relies on existing evaluation pipelines (FactScore), the application to sentence-level alignment without pairwise preference data is a practical advancement for long-form factuality.