📝 Paper Summary
Hallucination evaluation
Factuality benchmarking
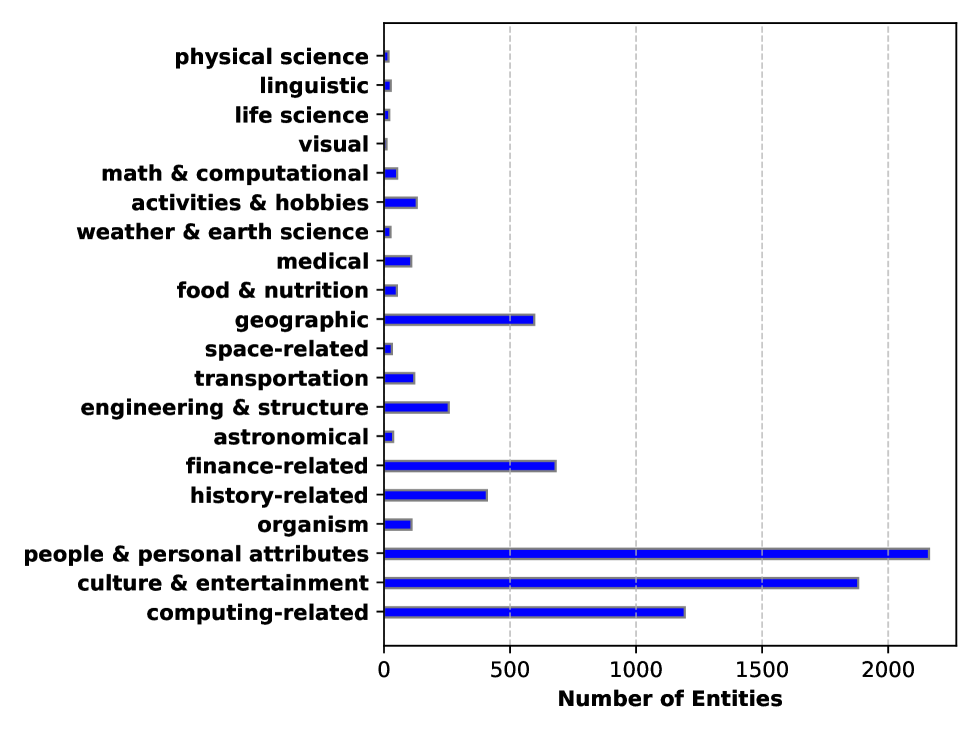
WildHallucinations evaluates LLM factuality using 7,919 real-world entities mined from user chat logs, revealing that models hallucinate significantly more on entities without Wikipedia pages.
Core Problem
Existing factuality benchmarks rely heavily on Wikipedia entities, failing to cover the diverse, niche, and non-Wikipedia topics that real users actually ask chatbots about.
Why it matters:
- Benchmarks based solely on Wikipedia overestimate model performance because training data often over-represents Wikipedia content
- Real-world users seek information on niche entities (people, finance) where hallucination rates are higher and more dangerous
- Current evaluations do not account for the long tail of rare entities where models are most prone to failure
Concrete Example:
A user might ask about a specific financial entity or a person without a Wikipedia page. While an LLM might recite a Wikipedia biography perfectly, it may hallucinate details about this lesser-known entity because it lacks the strong parametric knowledge present for Wikipedia topics.
Key Novelty
Evaluation on 'Wild' Entities via Automated Fact-Checking
- Extracts entities directly from real-world user-chatbot conversations (WildChat) rather than curating from Wikipedia
- Constructs ad-hoc knowledge sources by scraping top-10 web search results for each entity, enabling verification of non-Wikipedia subjects
- Evaluates factuality using atomic claim decomposition (FActScore) against these retrieved web documents
Architecture

The data construction and evaluation pipeline for WildHallucinations.
Evaluation Highlights
- GPT-4o and GPT-3.5 achieve the highest WildFActScore-Strict, outperforming other models by ~6 percentage points
- Retrieval-augmented models (Sonar-Large) can perform worse than their base models (Llama-3-70B) despite having access to web search
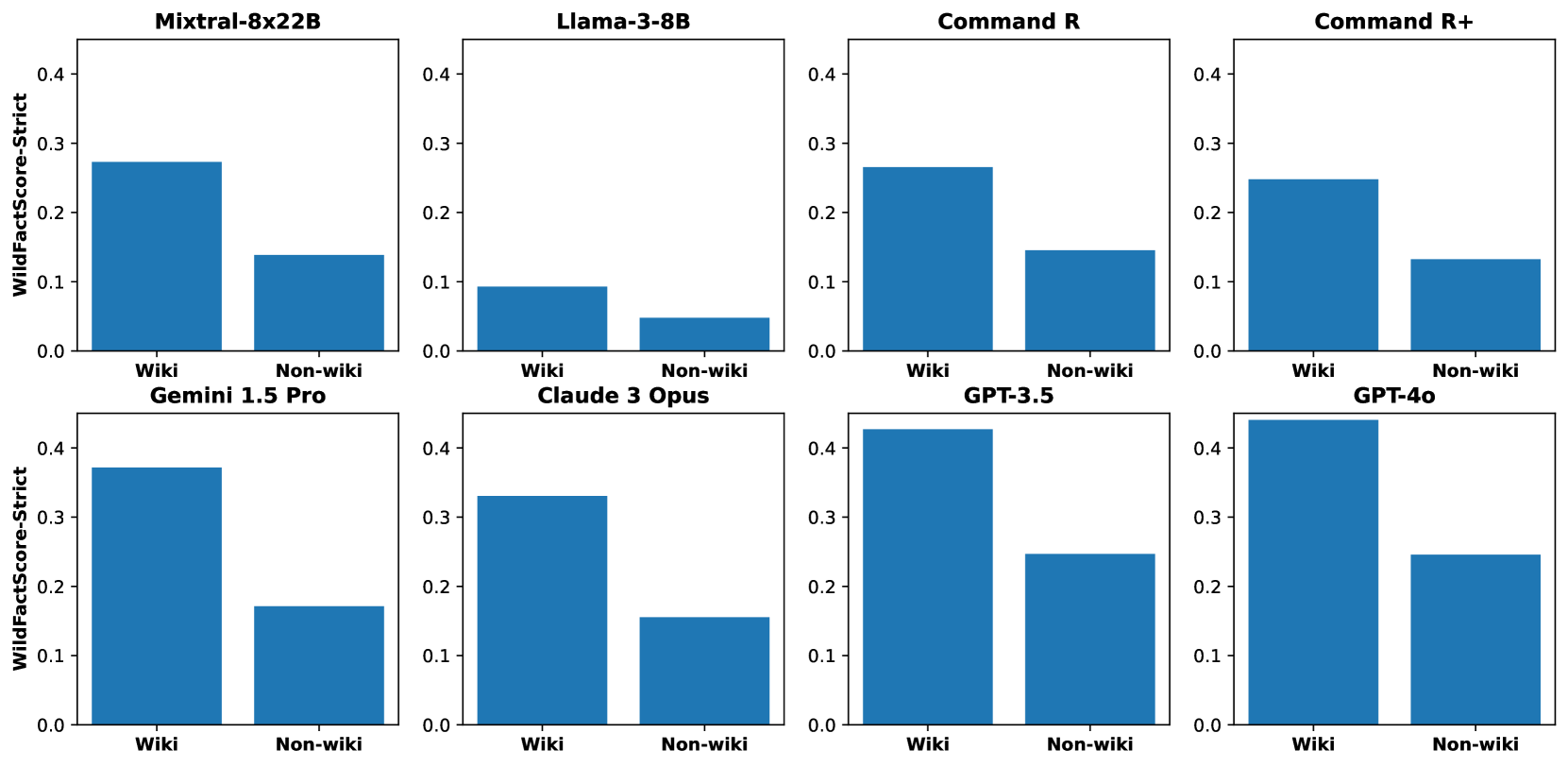
- Factuality drops significantly for all models on entities without Wikipedia pages; GPT-4o shows a major performance gap between Wiki vs. non-Wiki entities
Breakthrough Assessment
8/10
Strong contribution by shifting evaluation to real-world usage distributions. Highlighting the Wiki vs. non-Wiki gap is critical for understanding true model reliability.