📝 Paper Summary
Agentic RAG pipeline
RL-based tool use
DeSA improves search agents by decoupling training into two stages: first maximizing retrieval recall to learn search skills, then optimizing exact-match answer accuracy.
Core Problem
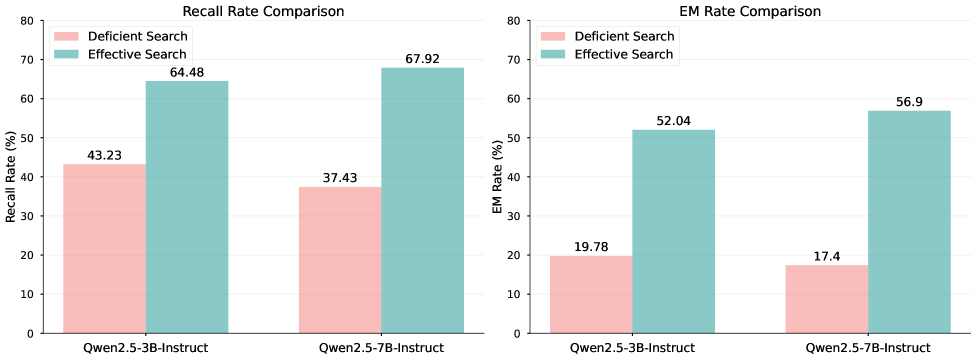
Training search agents solely with outcome-based rewards (like final answer accuracy) fails to teach effective intermediate search behaviors, leading to inefficiencies.
Why it matters:
- Outcome-only supervision provides sparse, delayed feedback, causing credit assignment challenges where agents don't learn which specific actions led to success
- Ineffective search behaviors (e.g., duplicate queries, invalid tool calls) persist even when final answer accuracy improves slightly, capping overall potential
- Current single-stage RL methods assume optimizing final answers implicitly optimizes search, but empirical analysis proves this assumption false
Concrete Example:
A Qwen2.5-3B agent trained only on outcome rewards might skip searching entirely (relying on parametric memory) or issue the same query multiple times, wasting resources. In contrast, DeSA forces the agent to first demonstrate it can find the relevant documents before trying to answer.
Key Novelty
DeSA (Decoupling Search and Answering)
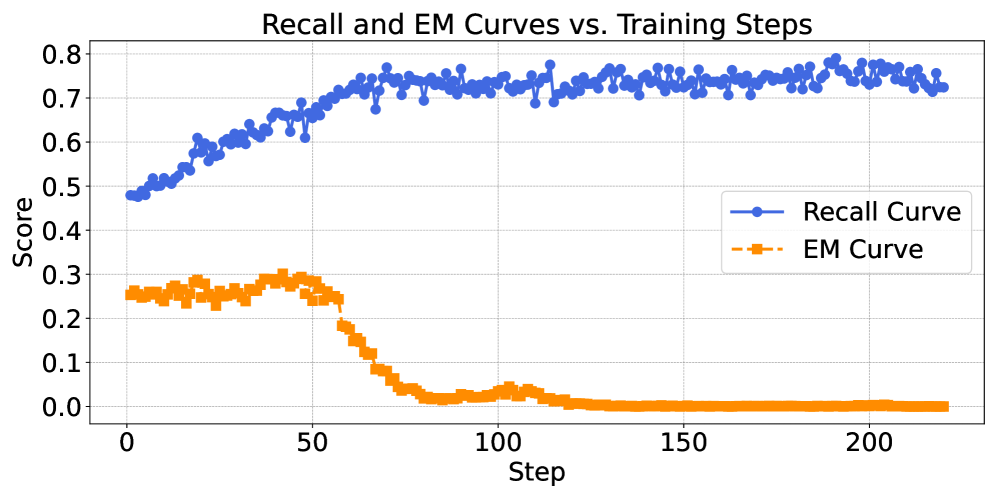
- Two-stage RL framework: Stage 1 strictly rewards finding relevant documents (Recall Reward) to establish search competence
- Stage 2 switches to outcome-based rewards (Exact Match) to refine answer generation, initializing from the competent searcher developed in Stage 1
- Prevents the 'reward hacking' observed in single-stage methods where agents learn to answer without searching or develop degenerate search patterns
Architecture
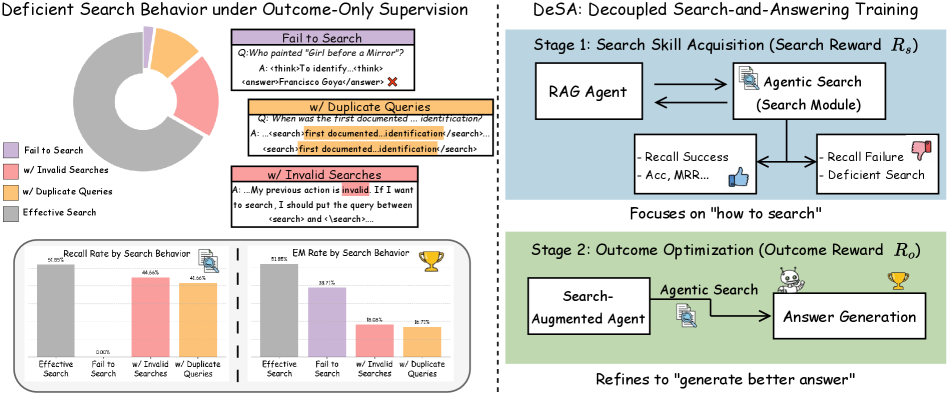
The two-stage training process of DeSA
Evaluation Highlights
- +8.0% average score improvement over Search-R1 baseline using Qwen2.5-3B-Instruct across 7 QA benchmarks
- +11.5 absolute point improvement on the Bamboogle benchmark (0.347 vs 0.232) using Qwen2.5-3B-Instruct
- Reduces deficient search rate from 23.36% (Search-R1) to 6.96% (DeSA) on Qwen2.5-3B-Instruct
Breakthrough Assessment
8/10
Strong empirical evidence debunking the common assumption that outcome rewards suffice for tool-use. Simple, effective two-stage solution with significant gains.