📊 Experiments & Results
Evaluation Setup
Fine-tune models of varying sizes on D2T datasets, measure factual inconsistency, and fit scaling laws.
Benchmarks:
- E2E (MR-to-text (Restaurant domain))
- ViGGO (MR-to-text (Video game domain))
- WikiTableText (Table-to-text (Open domain))
- DART (Graph-to-text (Open domain))
- WebNLG (RDF-to-text (Open domain))
Metrics:
- AlignScore
- QAFactEval
- SummaC-conv
- UniEval-fact
- Statistical methodology: 3-stage framework: (1) Predictive performance (5-fold CV Huber loss), (2) Goodness-of-fit (F-test, p<0.05), (3) Comparative analysis (Vuong’s likelihood-ratio test, p<0.005)
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparative analysis results using Vuong's test across datasets and metrics consistently favor the Exponential model over the Power Law model. | ||||
| E2E (Pythia Family) | Vuong's Test Decision (AlignScore) | Rejected | Selected | Exponential Preferred |
| ViGGO (OPT Family) | Vuong's Test Decision (AlignScore) | Rejected | Selected | Power Law Preferred |
| DART (Pythia Family) | Vuong's Test Decision (QAFactEval) | Rejected | Selected | Exponential Preferred |
| E2E (BLOOM Family) | F-Test Status (AlignScore) | Not reported in the paper | Not Qualified | Failed |
Experiment Figures
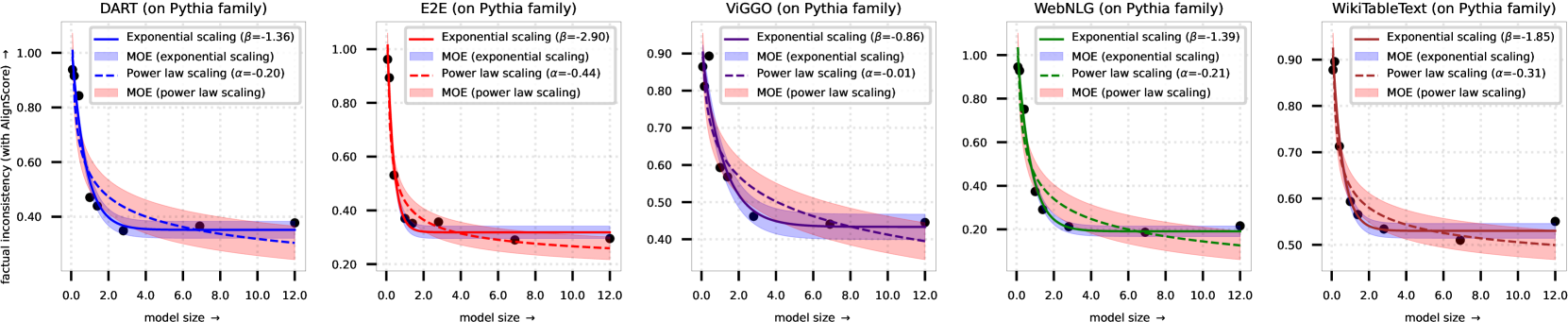
Fitted curves for Power Law vs. Exponential Scaling on AlignScore across all datasets and models.
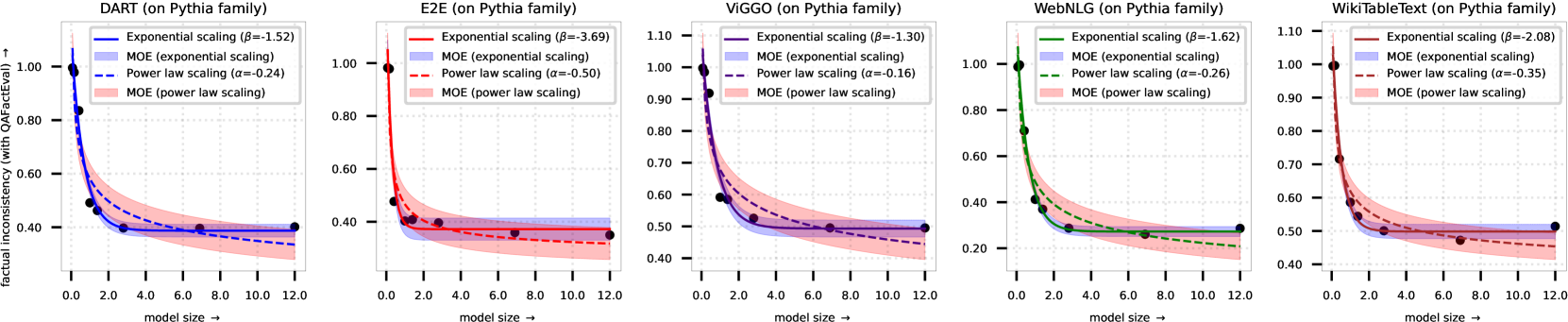
Fitted curves for Power Law vs. Exponential Scaling on QAFactEval.
Main Takeaways
- Factual inconsistency in D2T generally follows an exponential scaling law with respect to model size, rather than the power law observed for perplexity.
- This trend holds across different metrics (AlignScore, QAFactEval, etc.) and model families (Pythia, OPT), with high statistical significance.
- The BLOOM model family exhibits more irregular behavior, often failing goodness-of-fit tests for both scaling laws on certain datasets (e.g., E2E).
- Predictive performance (low Huber loss) is necessary but not sufficient for validating a scaling law; formal goodness-of-fit tests are crucial.