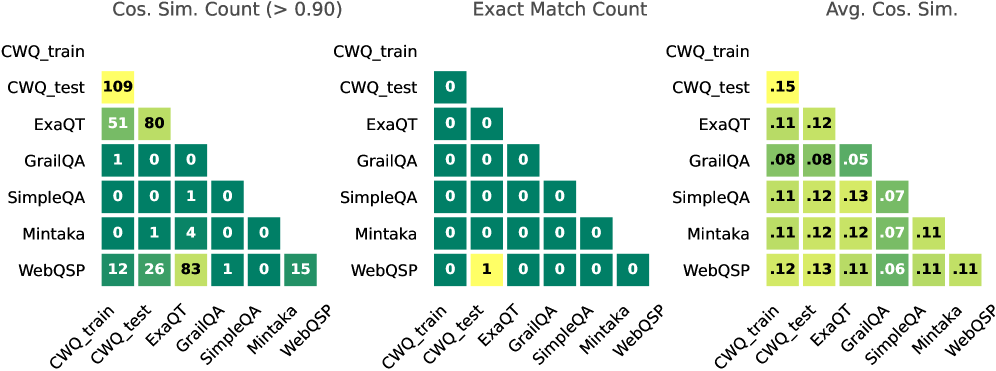
📝 Paper Summary
Factuality
Reasoning
The authors fine-tune small language models on reasoning traces distilled from large models but grounded in verifiably correct Knowledge Graph paths, significantly improving factuality in multi-hop question answering.
Core Problem
Large reasoning models generate 'thinking' traces that improve performance but may contain factual hallucinations, and smaller models struggle to perform complex multi-hop reasoning reliably.
Why it matters:
- Factual consistency is mandatory for critical real-world applications
- Distilled reasoning traces from larger models often lack a verification mechanism, potentially propagating hallucinations to smaller student models
- Current reasoning techniques prioritize problem-solving logic (like math) over verifiable factual accuracy in open-domain QA
Concrete Example:
A reasoning model might correctly answer 'Pablo Picasso' but hallucinate the wrong intermediate reasoning steps about his art movement associations. Without grounding, a fine-tuned student model learns this flawed logic.
Key Novelty
fs1 (Factual Simple Test-time Scaling)
- Extract reasoning traces from large models (e.g., DeepSeek-R1) for complex questions.
- Condition these traces on linearized Knowledge Graph paths retrieved from Wikidata to enforce factual accuracy in the reasoning steps.
- Fine-tune smaller standard LLMs (e.g., Qwen2.5-Instruct) on these verifiable, grounded traces to induce reliable reasoning capabilities.
Architecture

Conceptual overview of the fs1 method: extraction of raw traces, grounding with KG paths, and fine-tuning student models.
Evaluation Highlights
- +6 to +14 absolute points improvement (pass@16) on Qwen2.5-32B across six benchmarks compared to standard instruction-tuned baselines.
- Smaller models (e.g., 0.5B) show massive relative gains (up to +74.6% on WebQSP) from grounded fine-tuning, while larger models see diminishing returns.
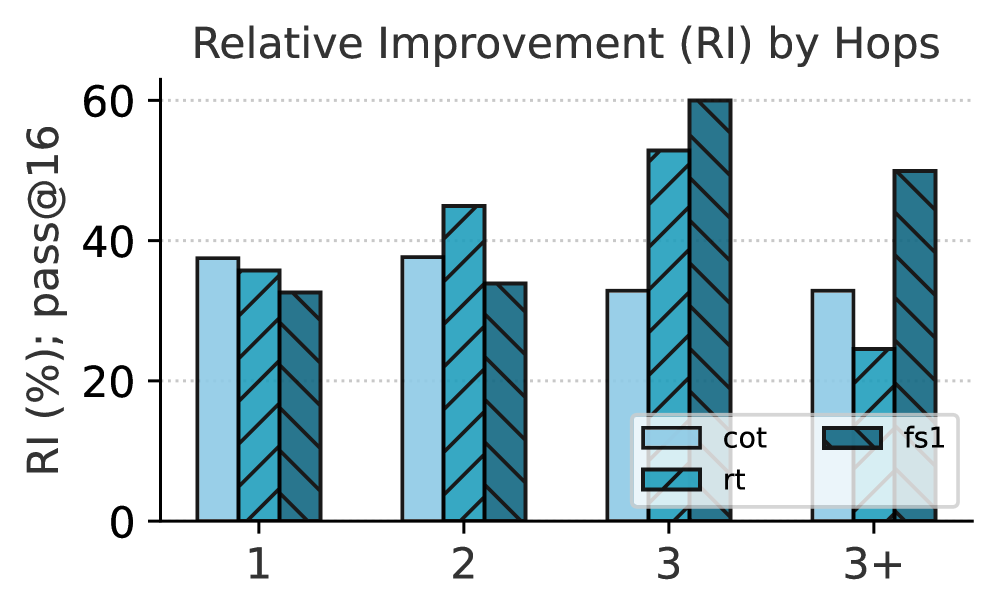
- Outperforms baselines specifically on complex questions requiring 3+ hops of reasoning and on numerical answer types.
Breakthrough Assessment
7/10
Strong empirical results demonstrating that KG grounding effectively cleans reasoning traces for distillation. While the method combines existing components (distillation + KGs), the analysis of scaling and complexity is valuable.