📝 Paper Summary
Long-form generation evaluation
Hallucination detection
Factuality verification
The paper introduces a Chinese long-form factuality dataset (LongHalluQA) and a multi-agent debate verification system (MAD-Fact) that weighs facts by importance to better evaluate LLM hallucinations.
Core Problem
Existing factuality benchmarks focus on short-form English content, while single-model evaluators often hallucinate or fail to distinguish between crucial errors and minor details in long texts.
Why it matters:
- Long-form generation is critical for real-world applications (biomedicine, law) where hallucinations can spread misinformation
- Current metrics treat all claims equally, penalizing minor auxiliary errors as heavily as central factual contradictions
- A severe lack of comprehensive Chinese long-form benchmarks hinders the development and safety assessment of domestic LLMs
Concrete Example:
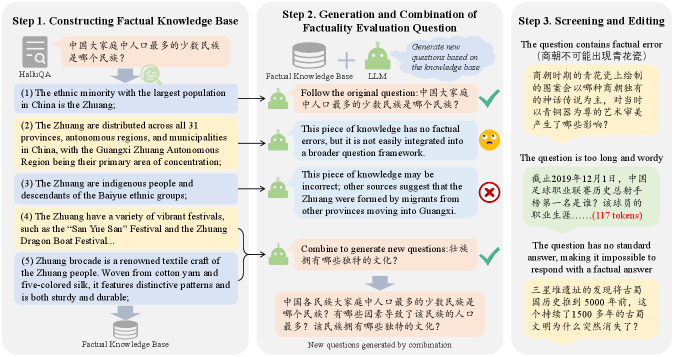
In a text about the Zhuang ethnic group, a model might correctly state their location (central fact) but error on a minor detail like a specific brocade pattern (auxiliary fact). Current metrics weight these errors identically, misrepresenting the text's overall reliability.
Key Novelty
Hierarchical Multi-Agent Debate for Weighted Factuality (MAD-Fact + LongHalluQA)
- Constructs a large-scale Chinese dataset by expanding short QA pairs into complex long-form queries using a knowledge-base-driven pipeline
- Employs a multi-agent debate system (Clerk, Jury, Judge) to verify claims, reducing the bias and inconsistency found in single-model evaluators
- Introduces a 'fact importance hierarchy' (inspired by the Pyramid Method) to assign different weights to claims, ensuring critical errors impact scores more than minor ones
Architecture
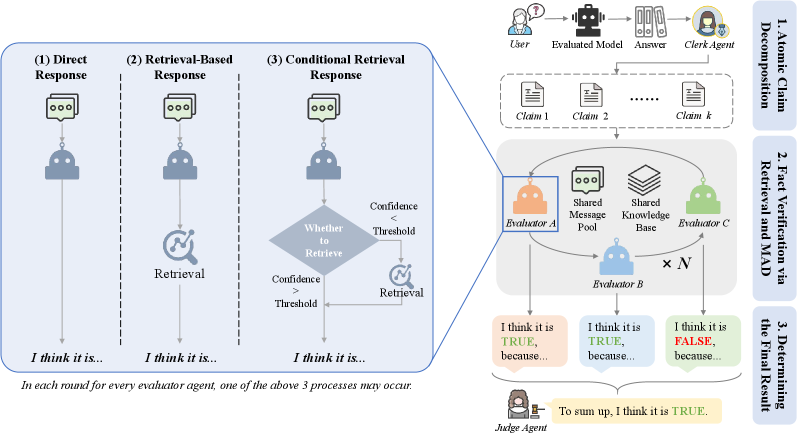
The MAD-Fact system architecture, detailing the multi-agent debate process.
Evaluation Highlights
- MAD-Fact metrics correlate strongly with human judgments (Pearson r=0.701), significantly better than unweighted approaches
- The constructed LongHalluQA dataset contains 2,746 samples with an average response length 9.4 times longer than original short-text datasets
- MAD-Fact consistently outperforms strong baselines like SAFE and FIRE on multiple long-form benchmarks
Breakthrough Assessment
8/10
Addresses a significant gap in non-English long-form evaluation. The combination of a new large-scale dataset, multi-agent verification, and importance-weighted metrics offers a comprehensive solution to hallucination measurement.