📝 Paper Summary
Knowledge internalization
Hallucination suppression
Prereq-Tune reduces hallucinations by separating fine-tuning into two stages: first learning prerequisite knowledge into a frozen adapter, then training a separate skill adapter that grounds its outputs on that knowledge.
Core Problem
Fine-tuning LLMs on data containing knowledge not seen during pre-training encourages the model to fabricate answers, creating a 'knowledge inconsistency' that leads to hallucination.
Why it matters:
- Standard fine-tuning entangles skill learning (e.g., how to write a biography) with knowledge acquisition (facts about the subject), confusing the model when it encounters unfamiliar entities
- Models are incentivized to produce plausible-looking but wrong answers when forced to generate facts they don't know during training
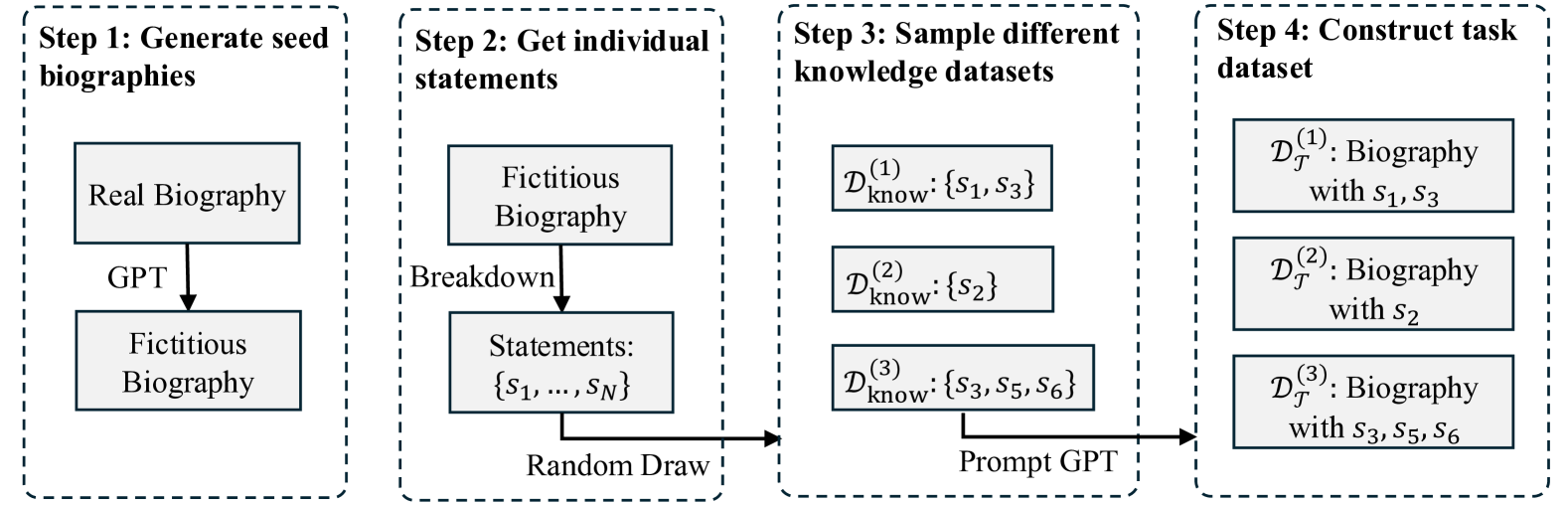
- Existing methods struggle to use synthetic data effectively because fictitious facts in synthetic data can pollute the model's factual knowledge base
Concrete Example:
If a model is fine-tuned to answer 'When was John Estes born?' with '1987', but never saw John Estes during pre-training, it learns to output a random year for any unknown person. Later, when asked about a real person it doesn't know, it hallucinates a birth year instead of abstaining.
Key Novelty
Two-Stage Disentangled Tuning (Prereq-Tune)
- First, train a 'Knowledge LoRA' on raw facts (prerequisite knowledge) needed for the task, then freeze it
- Second, train a 'Skill LoRA' on the actual downstream task (e.g., Q&A) while the Knowledge LoRA is active, forcing the skill module to rely on the provided knowledge
- During inference, the Knowledge LoRA is removed, and the Skill LoRA successfully generalizes to grounding answers in the model's original pre-trained knowledge
Architecture
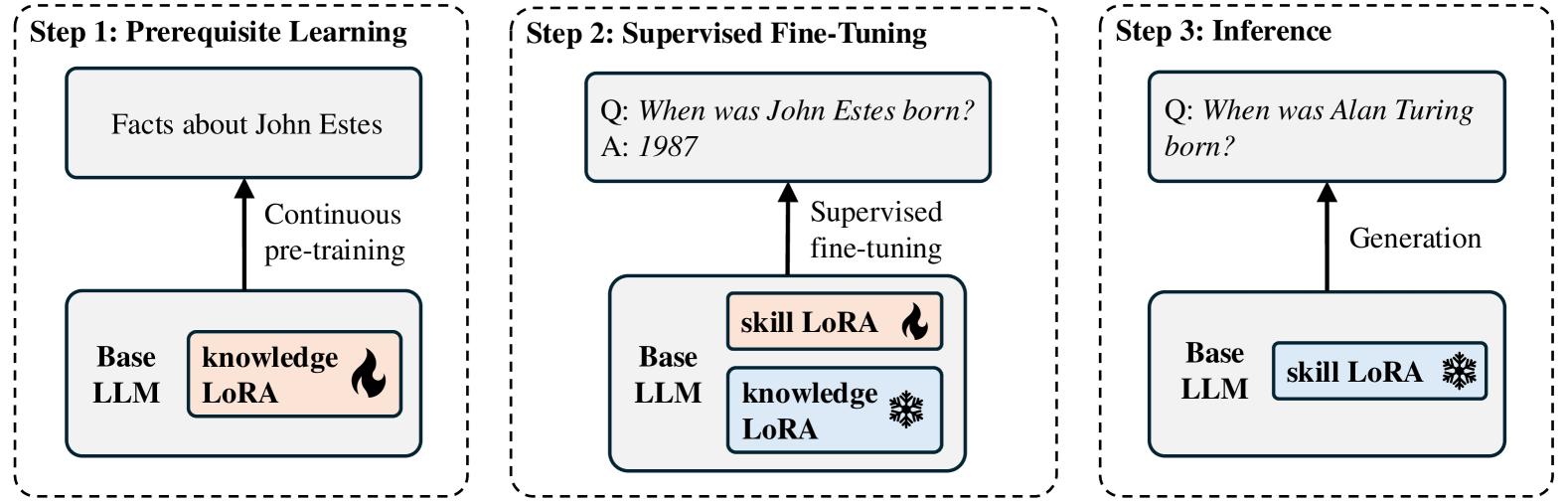
The two-stage training process of Prereq-Tune.
Evaluation Highlights
- Outperforms standard SFT by significantly reducing hallucination rate on biography generation (FactScore improvement not explicitly summarized as a single average but consistent across metrics)
- Successfully utilizes fictitious synthetic data (biographies of non-existent people) to improve factuality on real-world queries
- Demonstrates capability to switch answers based on which 'Knowledge LoRA' is plugged in, proving the skill module learns to ground generation rather than memorize facts
Breakthrough Assessment
8/10
Novel conceptual disentanglement of skill and knowledge using modular adapters. It turns the liability of fictitious synthetic data into an asset for training factual grounding.