📝 Paper Summary
Hallucination suppression
Internal state analysis
LLM Factoscope detects factual errors in LLM outputs without external knowledge bases by analyzing patterns in the model's inner states (activations, ranks, and probabilities) using a Siamese network.
Core Problem
LLMs frequently hallucinate non-factual content, and current detection methods rely on expensive external database cross-referencing or computationally heavy sampling.
Why it matters:
- Non-factual outputs in critical domains like medicine and law can cause harm to users
- Dependency on external knowledge bases introduces complexity and latency
- Existing internal methods like semantic uncertainty require repeated sampling, increasing computational overhead
Concrete Example:
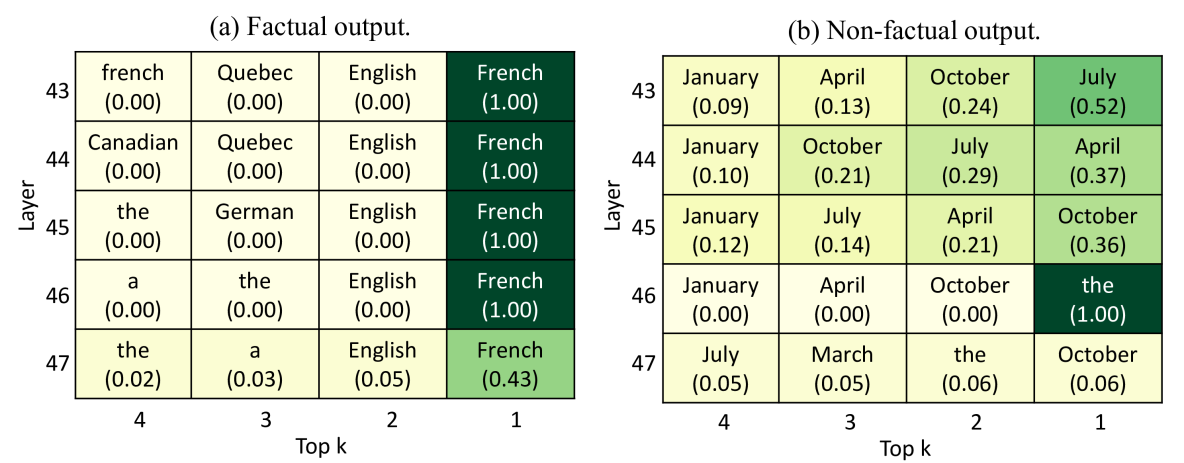
When asked 'The film titled The Shining was directed by', an LLM might confidently output 'Stanley Kubrick' (factual). If asked about 'The Beekeeper', it might output vague hallucinations. Factoscope aims to distinguish these using only the model's internal neural activations and output probabilities.
Key Novelty
LLM Lie Detector via Multi-view Inner States
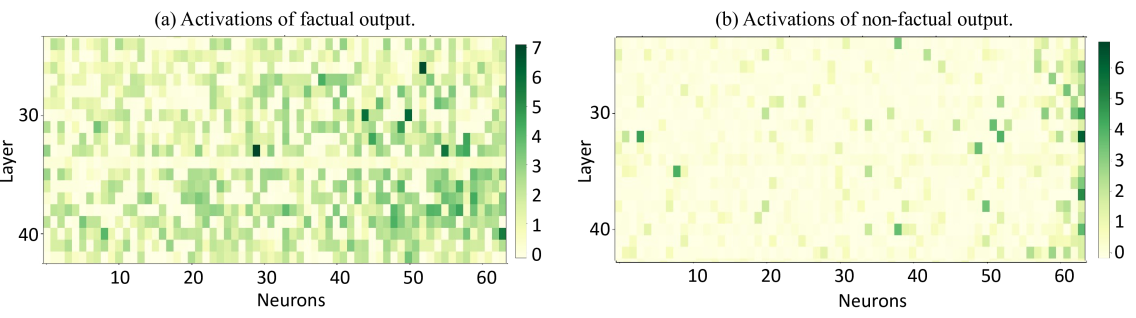
- Treats LLM hallucination detection like a human lie detector test by monitoring 'physiological' signals: activation maps and output dynamics
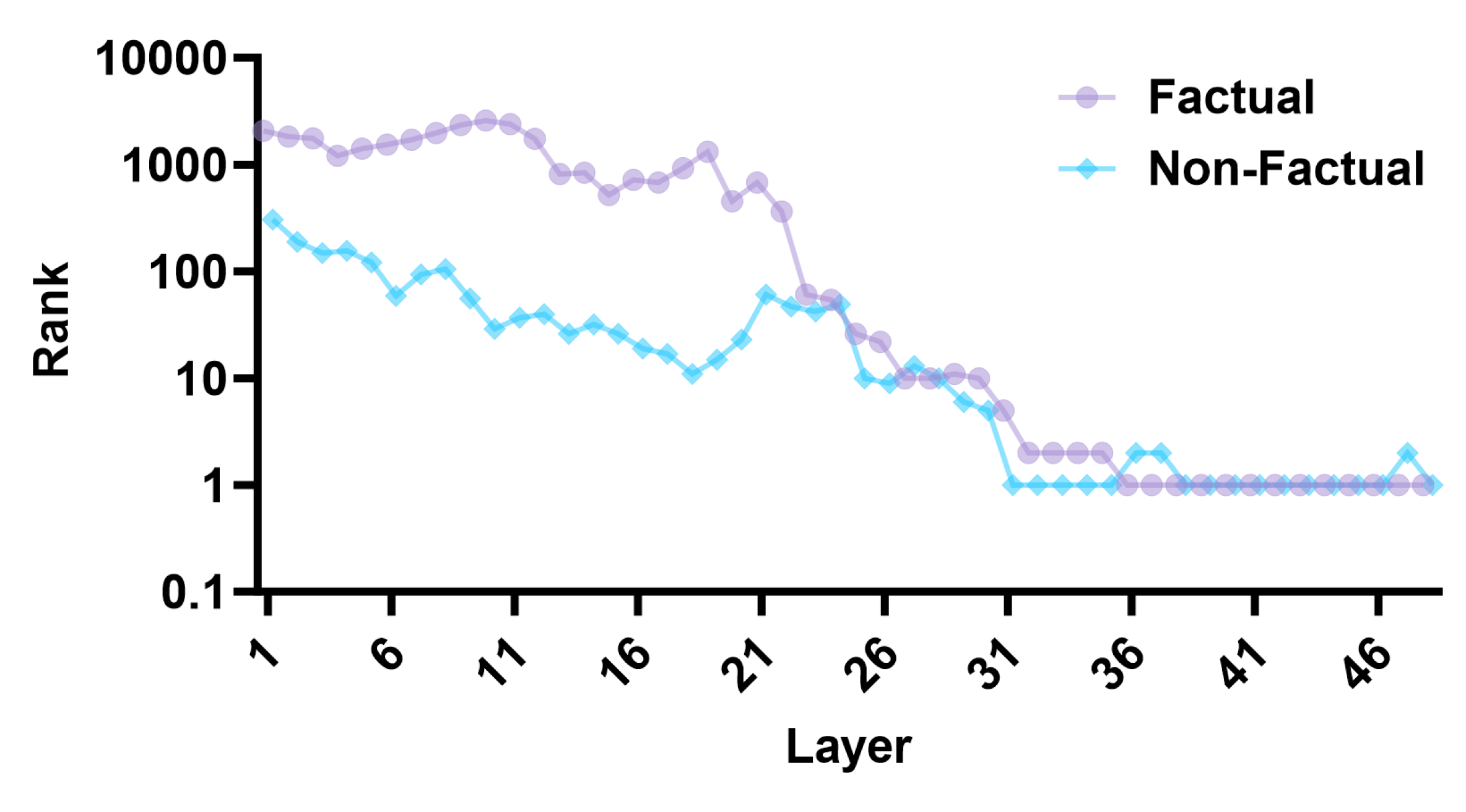
- Combines static features (neuron activation intensity) and dynamic features (evolution of output ranks/probabilities across layers) into a unified detection pipeline
- Uses a Siamese network with triplet margin loss to learn a metric space where factual and non-factual internal states are separable
Architecture
The LLM Factoscope pipeline: Data Collection -> Inner States Extraction -> Siamese Network Model.
Evaluation Highlights
- Achieves >96% accuracy on a custom-collected factual detection dataset across multiple architectures (Llama2, Vicuna, GPT2-XL)
- Outperforms unsupervised baselines like Min-k% Prob and unexpectedness metrics by significant margins
- Demonstrates strong generalization: a detector trained on Llama2-7B transfers effectively to other models like Vicuna-7B
Breakthrough Assessment
7/10
Strong empirical results (>96% accuracy) and a novel, resource-efficient approach that avoids external retrieval. However, reliance on a specific type of triplet-relation fact dataset may limit scope compared to free-form generation.