📝 Paper Summary
Generative Recommendation
Semantic ID-based Recommendation
RPG replaces autoregressive generation with parallel prediction of long, unordered semantic IDs, using a multi-token prediction loss and graph-constrained decoding to improve efficiency and expressiveness.
Core Problem
Existing generative recommenders rely on autoregressive decoding (generating one token at a time) and beam search, which forces the use of short, less expressive semantic IDs to maintain acceptable latency.
Why it matters:
- Current generative models suffer from high inference latency due to multiple forward passes (one per token) required for autoregressive generation.
- To mitigate latency, current models restrict semantic IDs to very short sequences (e.g., 4 tokens), which limits the semantic expressiveness of item representations compared to retrieval-based methods.
- Running standard beam search on expressive, long semantic IDs (e.g., 32+ tokens) is computationally prohibitive.
Concrete Example:
In TIGER, generating a recommendation requires 4 sequential forward passes because it uses 4-token IDs. If one wanted to use a more expressive 32-token ID (like VQ-Rec), TIGER would require 32 sequential forward passes and beam search steps, making real-time inference impossible.
Key Novelty
Parallel Semantic ID Generation with Graph-Constrained Decoding
- Treats semantic IDs as unordered sets of tokens rather than sequences, allowing the model to predict all tokens of the next item simultaneously in a single forward pass.
- Uses a graph-based decoding strategy during inference that connects semantically similar IDs, enabling efficient traversal of the candidate space without enumerating all items.
Architecture
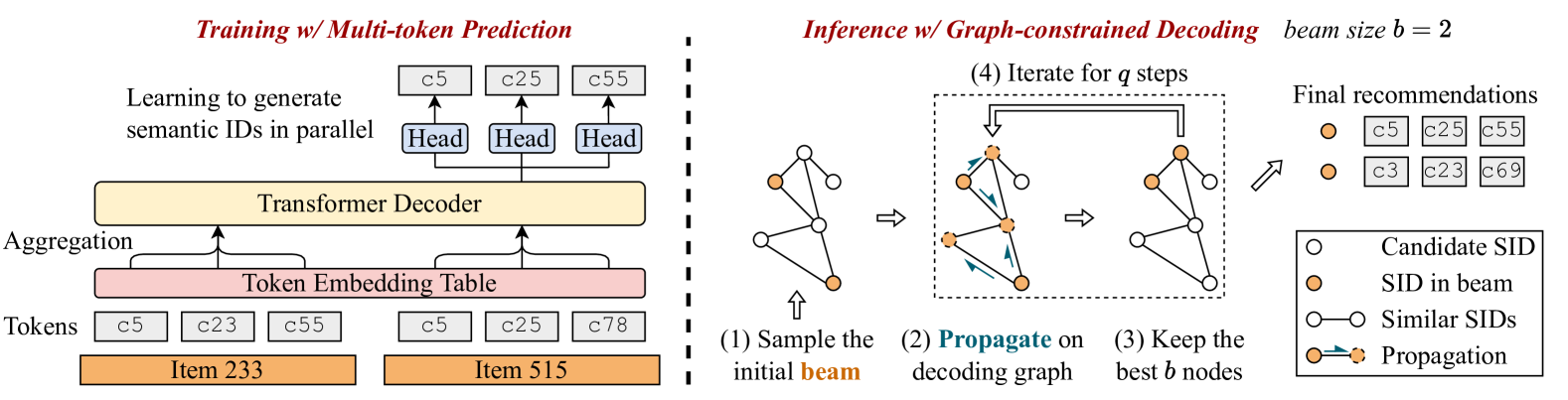
The overall framework of RPG, illustrating the transition from Item Quantization to Parallel Generation and Graph Decoding.
Evaluation Highlights
- Outperforms generative baselines by an average of 12.6% on NDCG@10 across benchmarks by scaling semantic ID length to 64 tokens.
- Reduces inference time complexity to be independent of the total number of items, unlike retrieval baselines.
- Achieves O(1) sequence encoder forward passes per recommendation, compared to O(b*m) for autoregressive models like TIGER.
Breakthrough Assessment
8/10
Significantly addresses the critical bottleneck of generative recommendation (latency) while simultaneously improving performance via longer IDs. The shift from autoregressive to parallel generation for semantic IDs is a strong methodological pivot.