📝 Paper Summary
Hallucination suppression
Preference Learning / Alignment
Mask-DPO improves LLM factuality by using sentence-level annotations to mask out incorrect sentences in preferred responses and correct sentences in non-preferred responses during Direct Preference Optimization training.
Core Problem
Standard DPO optimizes at the response level, meaning it inadvertently encourages hallucinations present in 'preferred' responses and penalizes factual statements present in 'non-preferred' responses.
Why it matters:
- LLM responses often contain a mix of truth and hallucination, creating ambiguity when an entire response is labeled simply as 'better' or 'worse'
- This noise in the training signal limits the effectiveness of alignment, preventing models from distinguishing fine-grained factual nuances
- Existing methods rely on coarse response-level rewards, which fails to precisely target the specific sentences responsible for hallucinations
Concrete Example:
If a preferred response contains 9 correct sentences and 1 hallucination, vanilla DPO increases the probability of the hallucination along with the truth. Conversely, if a rejected response has mostly errors but 1 correct fact, DPO decreases the probability of that correct fact.
Key Novelty
Mask-DPO (Masked Direct Preference Optimization)
- Introduces a masking mechanism into the DPO loss function that leverages sentence-level factuality annotations
- Prevents the model from learning from incorrect sentences within 'winning' samples by masking their contribution to the loss
- Prevents the model from being penalized for correct sentences within 'losing' samples, resolving the ambiguity of mixed-quality responses
Architecture
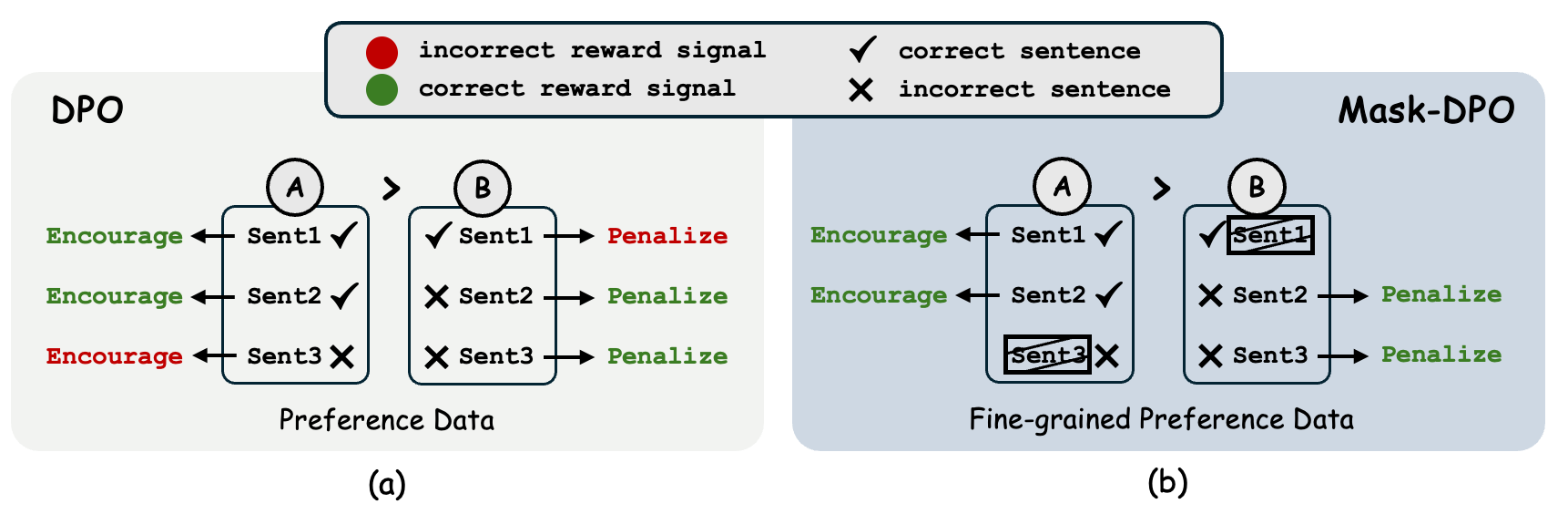
Conceptual comparison between standard DPO and Mask-DPO. Standard DPO optimizes the entire preferred response (green) and suppresses the entire rejected response (red). Mask-DPO applies a mask based on sentence-level factuality.
Evaluation Highlights
- Improves Llama3.1-8B-Instruct on the ANAH test set from 49.19% to 77.53%, surpassing the larger Llama3.1-70B-Instruct (53.44%)
- Outperforms standard DPO (68.44%) and FactTune (56.83%) on in-domain factuality benchmarks
- Generalizes to out-of-domain biography generation, improving FactScore from 30.29% to 39.39% without training on biography data
Breakthrough Assessment
8/10
Offers a simple yet highly effective modification to DPO that addresses a fundamental flaw in response-level preference learning for factuality. Significant gains over much larger models.