📝 Paper Summary
LLM Factuality Evaluation
Automated Fact-Checking
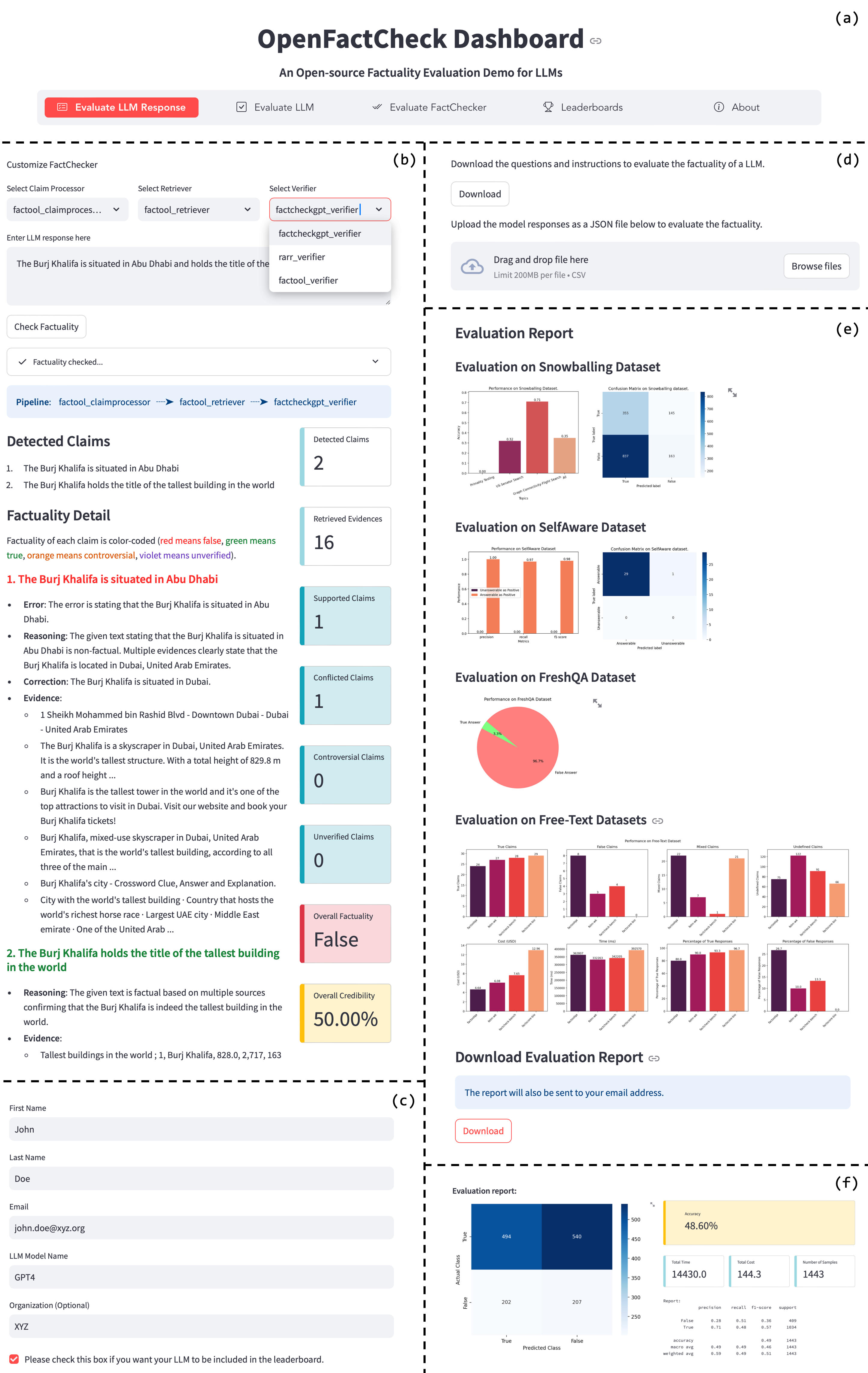
OpenFactCheck consolidates LLM factuality evaluation into a single modular framework that allows users to customize fact-checkers, benchmark LLM performance, and evaluate the accuracy of the fact-checkers themselves.
Core Problem
Evaluating LLM factuality is fragmented because different studies use different datasets and metrics, making comparisons difficult, while existing tools are often inaccessible to non-programmers.
Why it matters:
- Inconsistent benchmarks hamper progress in reducing hallucinations, as researchers cannot fairly compare new methods against state-of-the-art
- High-stakes applications (clinical, legal) require reliable verification, but current tools lack a unified interface for customizing checkers
- There is no standardized way to evaluate the accuracy of the fact-checkers themselves, leaving users unsure if the verification tool is reliable
Concrete Example:
When a user wants to verify a free-form document, they might need one tool for claim decomposition (like Factcheck-GPT) and another for retrieval (like FacTool), but existing implementations are hard-coded and incompatible. OpenFactCheck allows seamless combination of these distinct modules via a configuration file.
Key Novelty
Unified Modular Framework for Factuality (OpenFactCheck)
- Decomposes fact-checking into three standardized modules (ResponseEval, LLMEval, CheckerEval) that interact seamlessly
- Treats individual components (claim processors, retrievers, verifiers) as interchangeable plugins configurable via YAML, allowing users to mix-and-match best-in-class sub-modules from different systems
- Introduces FactQA (a unified question set) and FactBench (a unified checker benchmark) to standardize evaluation criteria across the field
Architecture
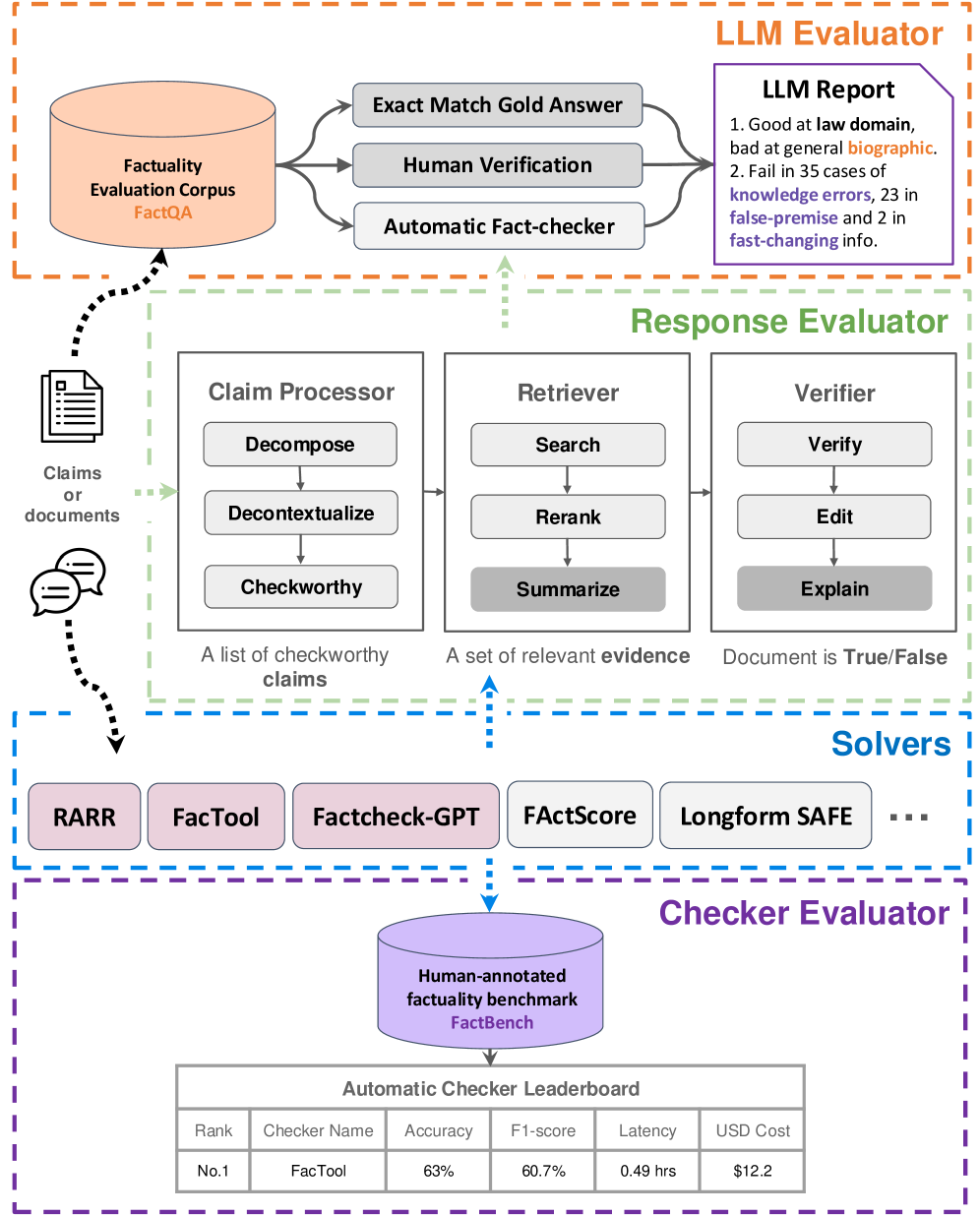
Overview of the OpenFactCheck framework showing the interaction between its three main modules.
Evaluation Highlights
- Aggregates 6,480 factual examples into FactQA from 7 distinct datasets to standardize LLM evaluation
- Consolidates 4 factuality benchmarks into FactBench to evaluate checker accuracy
- Provides a plug-and-play architecture supporting 3 major existing systems (RARR, FacTool, Factcheck-GPT) within a single interface
Breakthrough Assessment
7/10
Significant engineering contribution unifying a fragmented field. While it aggregates existing methods rather than proposing a novel algorithmic breakthrough, the unified framework and standardized benchmarks (FactQA/FactBench) are highly valuable for reproducibility.