📝 Paper Summary
Factuality evaluation
Long-form generation
LLM-as-a-judge
The paper introduces LongFact, a large-scale prompt set for long-form factuality, and SAFE, an automated evaluator using search-augmented LLMs that outperforms human crowdsourced annotators in cost and accuracy.
Core Problem
LLMs frequently hallucinate or produce factual errors in open-ended long-form responses, yet existing benchmarks focus on short answers or single factoids, making comprehensive evaluation difficult.
Why it matters:
- Current benchmarks like TruthfulQA or HaluEval mostly test short-answer factoids, failing to capture the complexity of multi-paragraph responses
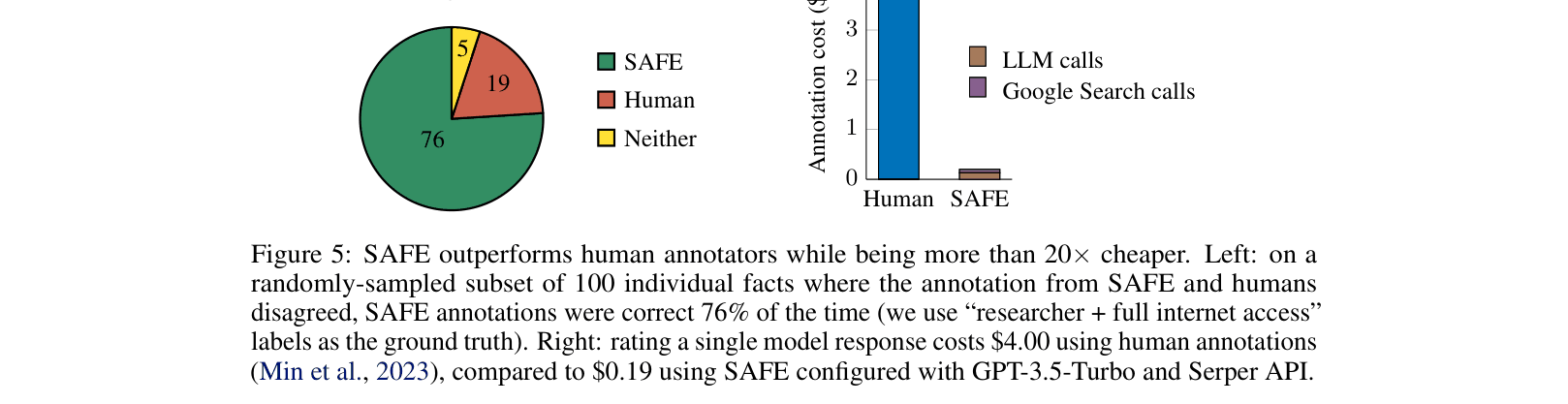
- Human annotation for long-form text is expensive ($4.00/response), slow, and hard to scale
- Existing automated metrics (BLEURT, ROUGE) rely on reference answers, which are difficult to compile for open-ended questions
Concrete Example:
When asked 'What is the Eiffel Tower?', an LLM might generate a paragraph with multiple claims. One sentence might correctly state it's in Paris, while another incorrectly claims it opened in the 20th century. Standard metrics evaluating the whole text against a reference summary often miss these fine-grained factual contradictions.
Key Novelty
Search-Augmented Factuality Evaluator (SAFE)
- Decomposes long-form responses into individual atomic facts using an LLM
- Uses a multi-step reasoning agent to generate Google Search queries for each fact and determine support based on search results
- Introduces F1@K, a metric balancing factual precision (supported facts) with recall (facts provided relative to a target length K)
Architecture
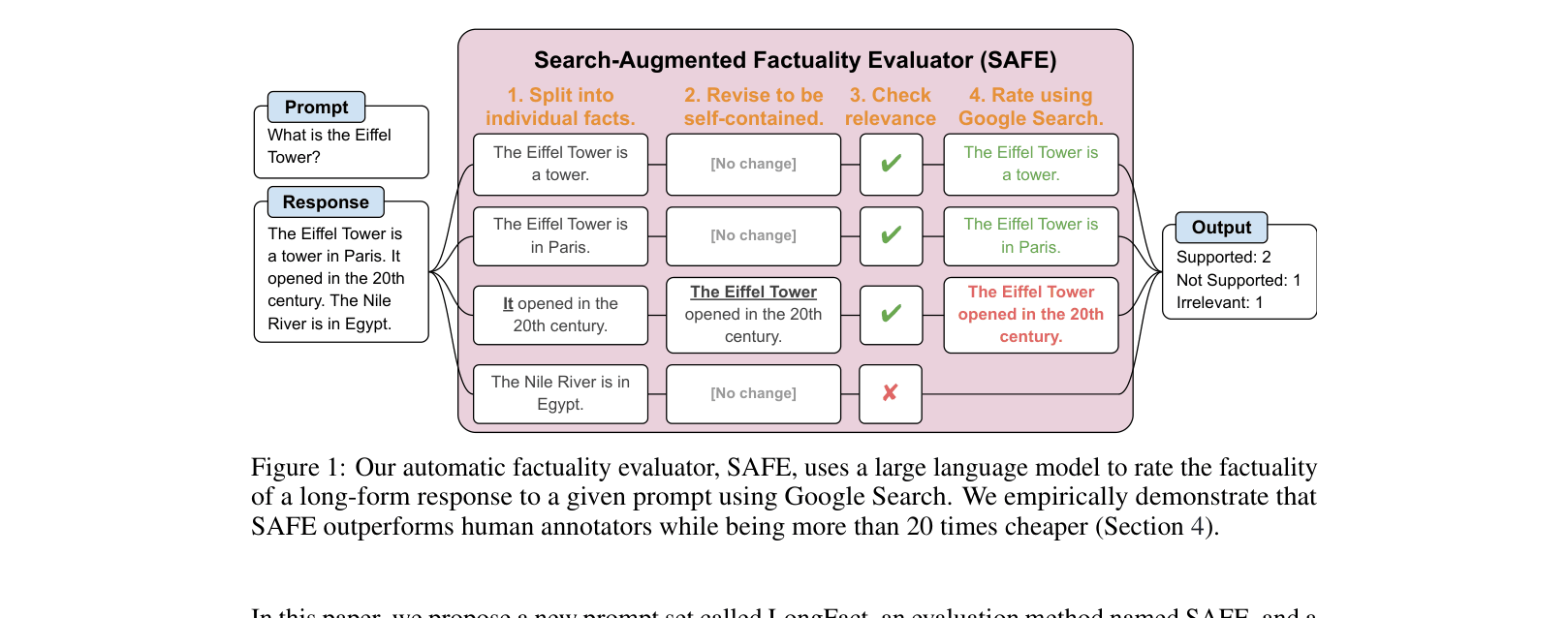
The 4-step workflow of the Search-Augmented Factuality Evaluator (SAFE)
Evaluation Highlights
- SAFE agrees with crowdsourced human annotators 72.0% of the time on a set of ~16k individual facts
- SAFE wins 76% of disagreement cases against crowdsourced human annotators (when ground truth is determined by researchers with full internet access)
- SAFE is more than 20 times cheaper than human annotators ($0.19 vs $4.00 per response)
Breakthrough Assessment
9/10
Significantly advances automated evaluation by demonstrating LLM agents can outperform crowdsourced humans for fact-checking. The release of a massive prompt set (LongFact) and the agent code addresses a major bottleneck in factuality research.