📊 Experiments & Results
Evaluation Setup
Zero-shot and Few-shot evaluation on standard NLP benchmarks.
Benchmarks:
- ARC-E (Science Question Answering)
- ARC-C (Science Question Answering (Challenge))
- HellaSwag (Commonsense Reasoning)
- PIQA (Physical Commonsense)
- WinoGrande (Commonsense Reasoning)
- OBQA (OpenBook Question Answering)
Metrics:
- Accuracy
- Statistical methodology: Spearman correlation used for scaling law validation. Significance tests for task results not explicitly reported.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| FLAME-MoE consistently outperforms dense baselines trained with identical compute budgets across various scales. | ||||
| Average (6 tasks) | Accuracy | 56.4 | 59.8 | +3.4 |
| Average (6 tasks) | Accuracy | 53.2 | 56.6 | +3.4 |
| Average (6 tasks) | Accuracy | 47.7 | 49.5 | +1.8 |
| HellaSwag | Spearman Correlation | Not explicitly reported in the paper | 0.89 | Not explicitly reported in the paper |
Experiment Figures
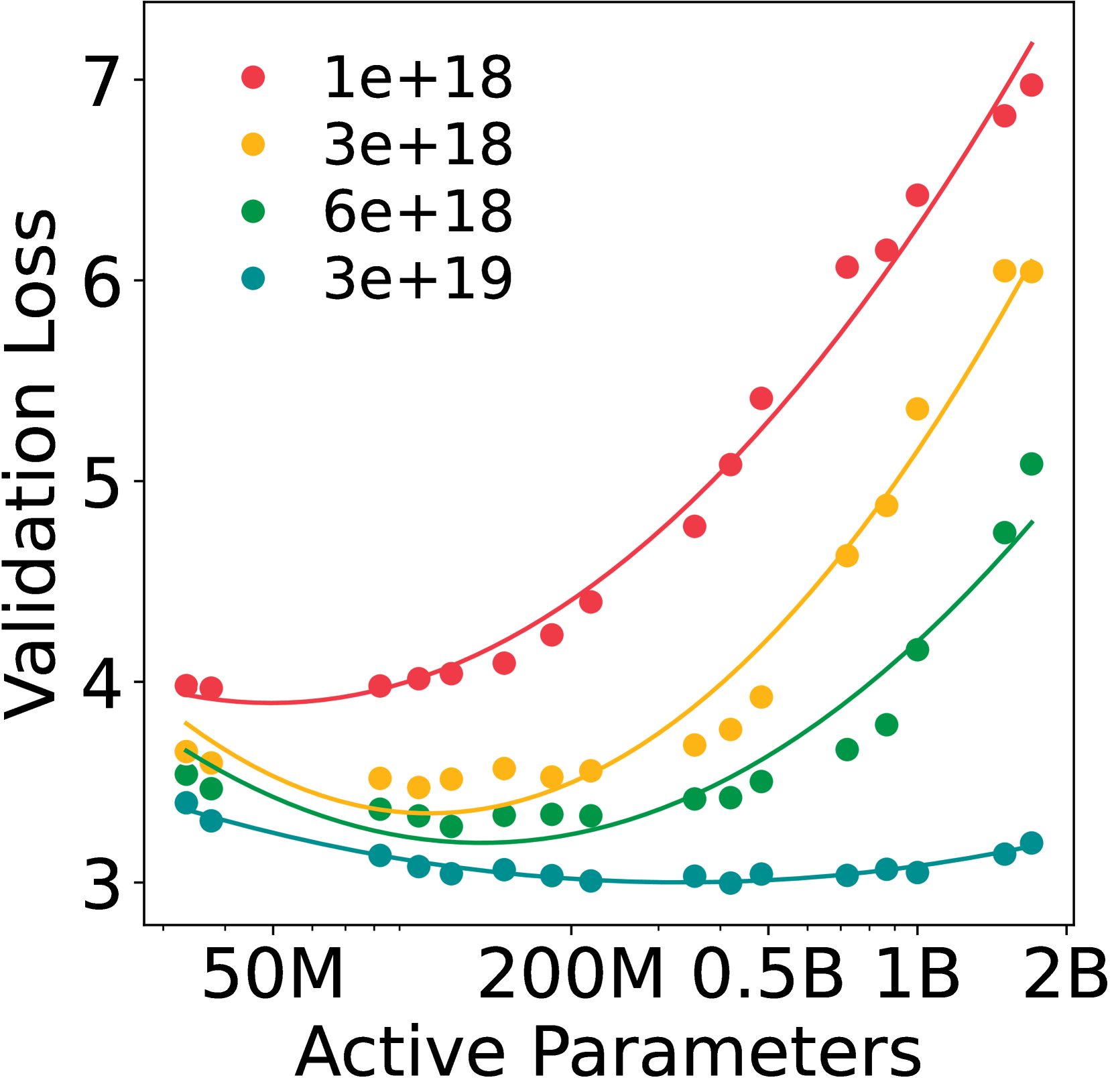
IsoFLOP profiles and scaling law fits. Shows validation loss vs. active parameters for fixed FLOP budgets.
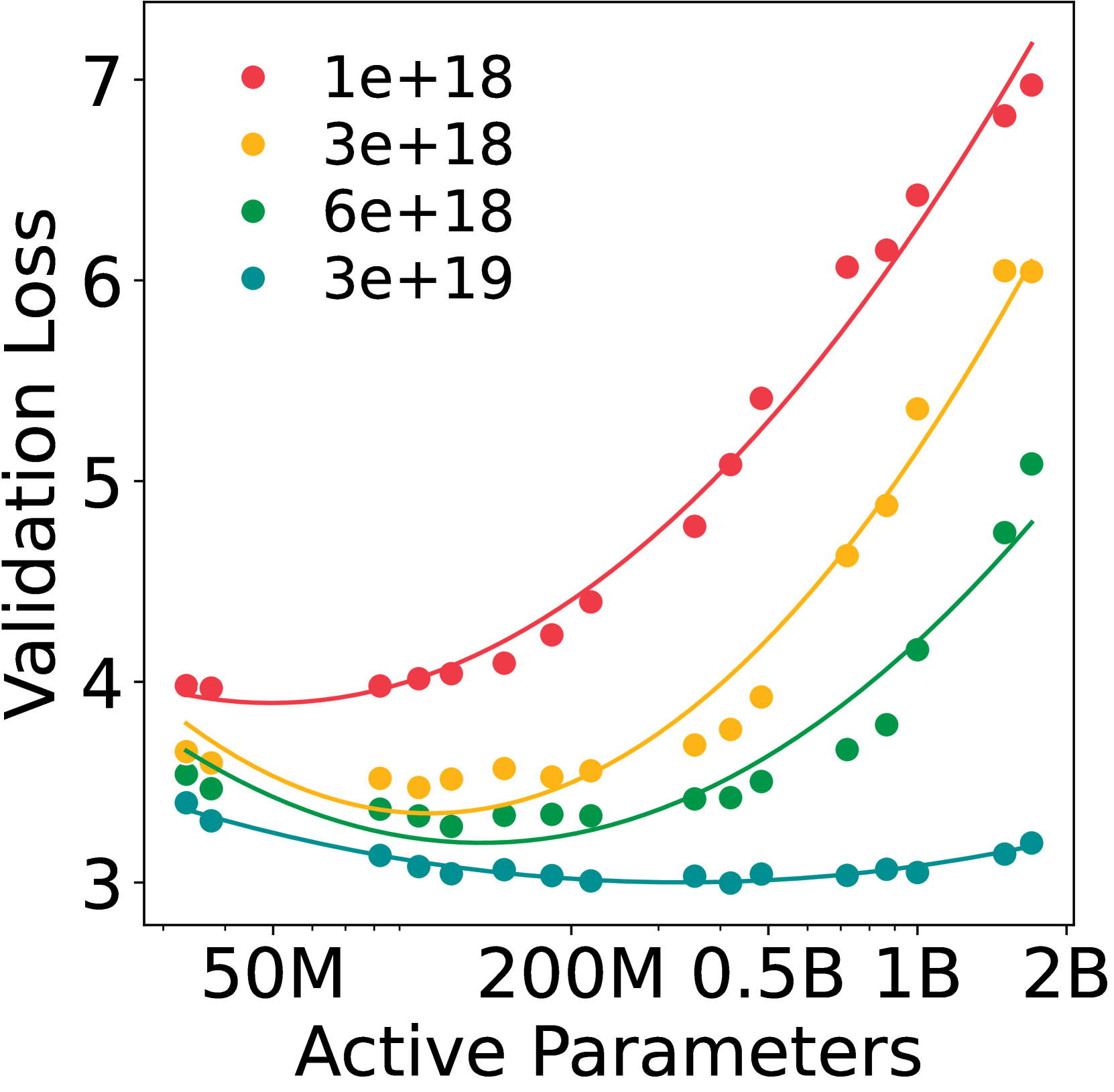
Scaling curves of FLAME-MoE vs Dense models (Accuracy vs Pretraining FLOPs).
Main Takeaways
- Compute-optimal MoE models consistently outperform dense models trained with the same FLOPs budget, with the gap widening at larger scales.
- Expert specialization happens early in training and intensifies over time, confirming that routing is not random.
- Routing patterns stabilize early, suggesting that the router quickly learns a consistent assignment strategy.
- Co-activation matrices remain sparse, indicating diverse expert usage rather than collapse to a few dominant experts.