📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Mathematical Reasoning
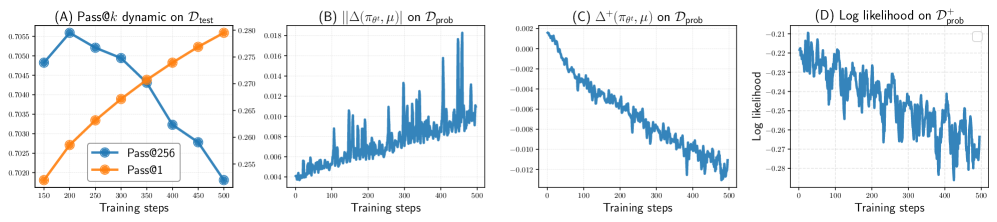
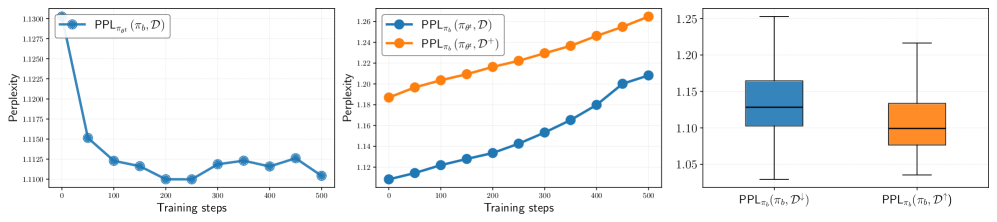
RLVR training paradoxically shrinks the set of solvable problems because on-policy sampling disproportionately reinforces already-high-likelihood solutions while negatively interfering with low-likelihood correct ones.
Core Problem
RLVR improves average accuracy (Pass@1) but often reduces the total number of problems a model can solve (coverage/Pass@k) by forgetting how to solve harder, low-likelihood problems.
Why it matters:
- Models should expand their reasoning capabilities to new problems, not just become more confident on problems they can already solve
- Decreasing Pass@k indicates a loss of diversity in reasoning strategies, limiting the model's robustness and exploration capability
- Current regularization techniques like KL divergence and clipping fail to prevent this 'winner-take-all' collapse
Concrete Example:
In the Minerva benchmark, Qwen2.5-Math starts with high accuracy using code-based reasoning but lower accuracy with natural language. During RLVR, it collapses entirely to natural language reasoning (the 'winner'), causing performance on code-solvable problems to degrade.
Key Novelty
SELF (Selective Examples with Low-likelihood and Forward-KL)
- Analyzes RLVR dynamics to reveal 'negative interference,' where updating the model to solve easy problems actively harms its ability to solve harder ones
- Identifies a 'winner-take-all' effect driven by on-policy sampling: the model reinforces the reasoning paths it already favors, ignoring valid but lower-probability paths
- Proposes a data curation strategy that explicitly targets problems with low initial likelihood of correctness to counter this bias
Architecture
Conceptual illustration of the 'Winner-Take-All' phenomenon in RLVR
Evaluation Highlights
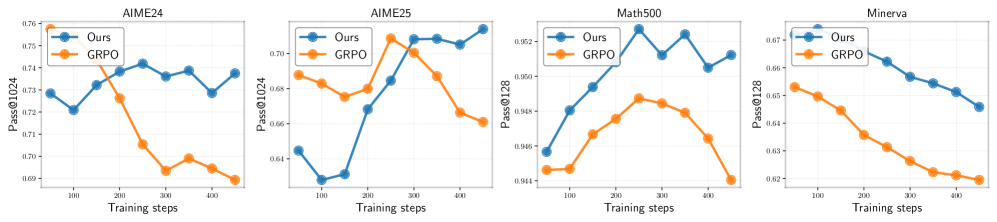
- SELF improves Pass@1 performance on AIME24 compared to standard RLVR (PPO/GRPO) baselines
- Standard RLVR shows a significant drop in Pass@256 (coverage) after ~300 steps, falling below the base model, while SELF mitigates this shrinkage
- Strong correlation observed between negative interference metrics and the decline in Pass@k performance across four mathematical benchmarks
Breakthrough Assessment
8/10
Provides a crucial theoretical and empirical explanation for the widely observed 'coverage shrinkage' in RLVR. The proposed solution is simple yet effective, directly addressing the identified mechanism.