📝 Paper Summary
Deep Research
Agentic Information Retrieval
Super Research is a rigorous benchmark for evaluating agentic deep research capabilities, requiring long-horizon planning and massive evidence synthesis to answer super-complex questions.
Core Problem
Current LLM evaluation paradigms fail to measure proficiency in solving highly complex, long-horizon research tasks that require synthesizing massive, conflicting evidence across hundreds of web pages.
Why it matters:
- Existing benchmarks prioritize atomic fact recall but neglect the sophisticated synthesis required for professional intelligence or scientific discovery
- Standard LLM-as-a-judge metrics often align poorly with deep reasoning quality, rewarding false confidence over necessary uncertainty expression
- Deep Research agents need a 'ceiling protocol' to stress-test limitations in reasoning consistency and context management that simpler tasks don't trigger
Concrete Example:
A question like 'optimizing immunopharmacological mechanisms where T cell activation must be balanced against tumor microenvironment immune escape' requires 100+ retrieval steps and synthesizing 1000+ pages, far exceeding the 10-20 steps of standard Wide/Deep Search.
Key Novelty
Super Research Benchmark & Graph-Anchored Auditing
- Defines a new tier of 'Super Research' requiring structured decomposition, super wide retrieval for diverse perspectives, and super deep investigation for uncertainty resolution
- Constructs a benchmark of 300 expert-written questions using a 'Cognitive-Rank Constrained Expert Simulation' followed by human verification
- Introduces a graph-anchored evaluation protocol where generated reports are projected onto expert-curated Knowledge Graphs to measure depth, logic, and objectivity
Architecture
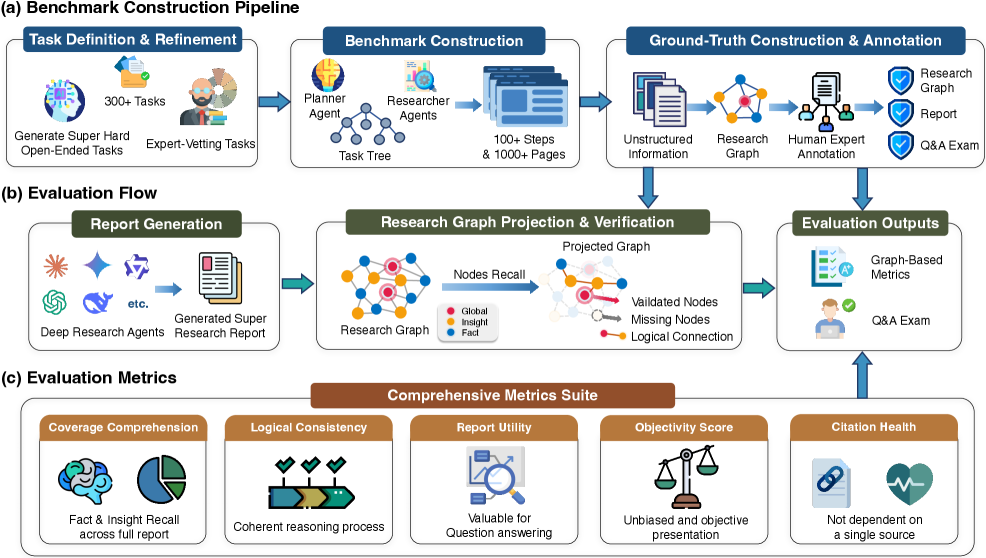
The expert-driven construction pipeline and the interactions between Planner, Researcher, Summarizer, and Writer agents
Evaluation Highlights
- SOTA system (Gemini Deep Research) achieves only 28.62 Overall Score, confirming the high difficulty ceiling of the benchmark
- Native Search-Integrated Agents like Kimi-k2 (26.16) outperform some specialized Deep Research systems and search-augmented baselines
- Standard agentic baselines (e.g., DeepSeek-r1 with Tavily) lag significantly, clustering in the 16-23 score range
Breakthrough Assessment
9/10
Establishes a critical 'ceiling' benchmark for the emerging field of Deep Research agents. The graph-anchored evaluation methodology is a significant advancement over standard LLM-as-a-judge approaches.