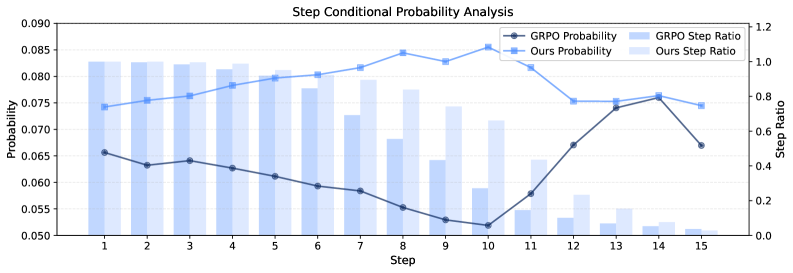
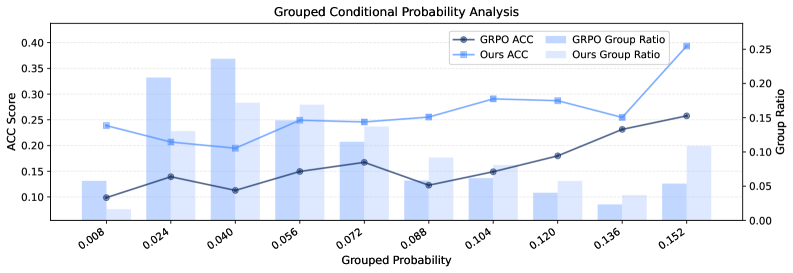
📝 Paper Summary
Memory organization
Linear memory management
MemPO enables agents to autonomously manage their own memory by incorporating memory-specific rewards into Group Relative Policy Optimization, ensuring retained information aligns with task objectives.
Core Problem
Existing agent memory methods rely on external storage or passive RAG, preventing the model from proactively learning which information is crucial for the specific task.
Why it matters:
- Fixed context windows limit the number of interactions an agent can have before crashing or forgetting
- External retrieval systems (RAG) often retrieve based on semantic similarity rather than task utility, fetching irrelevant data
- Long contexts cause 'lost in the middle' phenomenon and high token costs, hindering deployment in complex real-world scenarios
Concrete Example:
In a multi-step research task, a standard ReAct agent keeps appending every search result to the context. Eventually, the context exceeds the limit or the model gets distracted by early irrelevant searches, failing to answer the final question. RAG might retrieve a superficially similar but useless fact. MemPO, however, summarizes only the critical findings into a <mem> block at each step, discarding the rest.
Key Novelty
Self-Memory Policy Optimization (MemPO)
- Treats memory management as an intrinsic action (<mem> token generation) optimized via Reinforcement Learning rather than a fixed external module
- Introduces a dual-reward system: a sparse trajectory-level reward for final answer correctness and a dense step-level reward for memory quality
- Calculates memory quality by measuring how much the generated memory increases the model's conditional probability of generating the correct ground-truth answer
Architecture
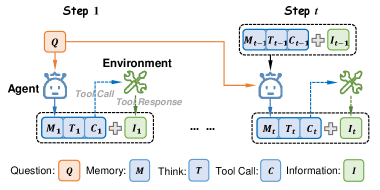
The MemPO interaction paradigm showing the cyclical process of memory update, reasoning, and tool use.
Evaluation Highlights
- +25.98% absolute F1 gain over the base model on long-horizon benchmarks
- +7.1% absolute F1 gain over the previous SOTA baseline (MEM1)
- Reduces token usage by 67.58% compared to the base model and 73.12% compared to previous SOTA
Breakthrough Assessment
8/10
Significant efficiency gains and performance improvements on long-horizon tasks by successfully applying RL directly to the memory management process, a difficult credit assignment problem.