📝 Paper Summary
Modularized RAG pipeline
Efficient Inference
Sparse RAG accelerates retrieval-augmented generation by encoding retrieved documents in parallel and dynamically filtering out irrelevant contexts during decoding using an integrated relevance assessment mechanism.
Core Problem
Standard RAG concatenates all retrieved documents into the input, causing latency to grow linearly with the number of documents (and quadratically for attention) while often including irrelevant noise.
Why it matters:
- Including many documents (e.g., 20+) causes dramatic latency increases, making real-time RAG applications on resource-constrained devices (like mobile phones) impractical
- Existing solutions like Fusion-in-Decoder (FiD) are incompatible with decoder-only LLMs, while Parallel Context Windows (PCW) speeds up pre-filling but still suffers from slow decoding due to full cache usage
- Reliance on external classifiers for filtering adds complexity and latency due to extra model calls
Concrete Example:
When a standard RAG system retrieves 20 documents, it must attend to all of them during every token generation step. If only 2 are relevant, the model wastes significant compute attending to 18 irrelevant documents, slowing down generation and potentially hallucinating based on noise.
Key Novelty
Dual-Task Integrated Sparse Retrieval
- Encodes retrieved documents in parallel (like PCW) to eliminate long-range cross-attention overhead during the pre-fill stage
- Integrates a 'Per Context Assessment' (PCA) task where the LLM scores the relevance of each document to the query within the same forward pass
- Selectively loads only the Key-Value (KV) caches of highly relevant documents for the decoding stage, significantly reducing the active context size
Architecture
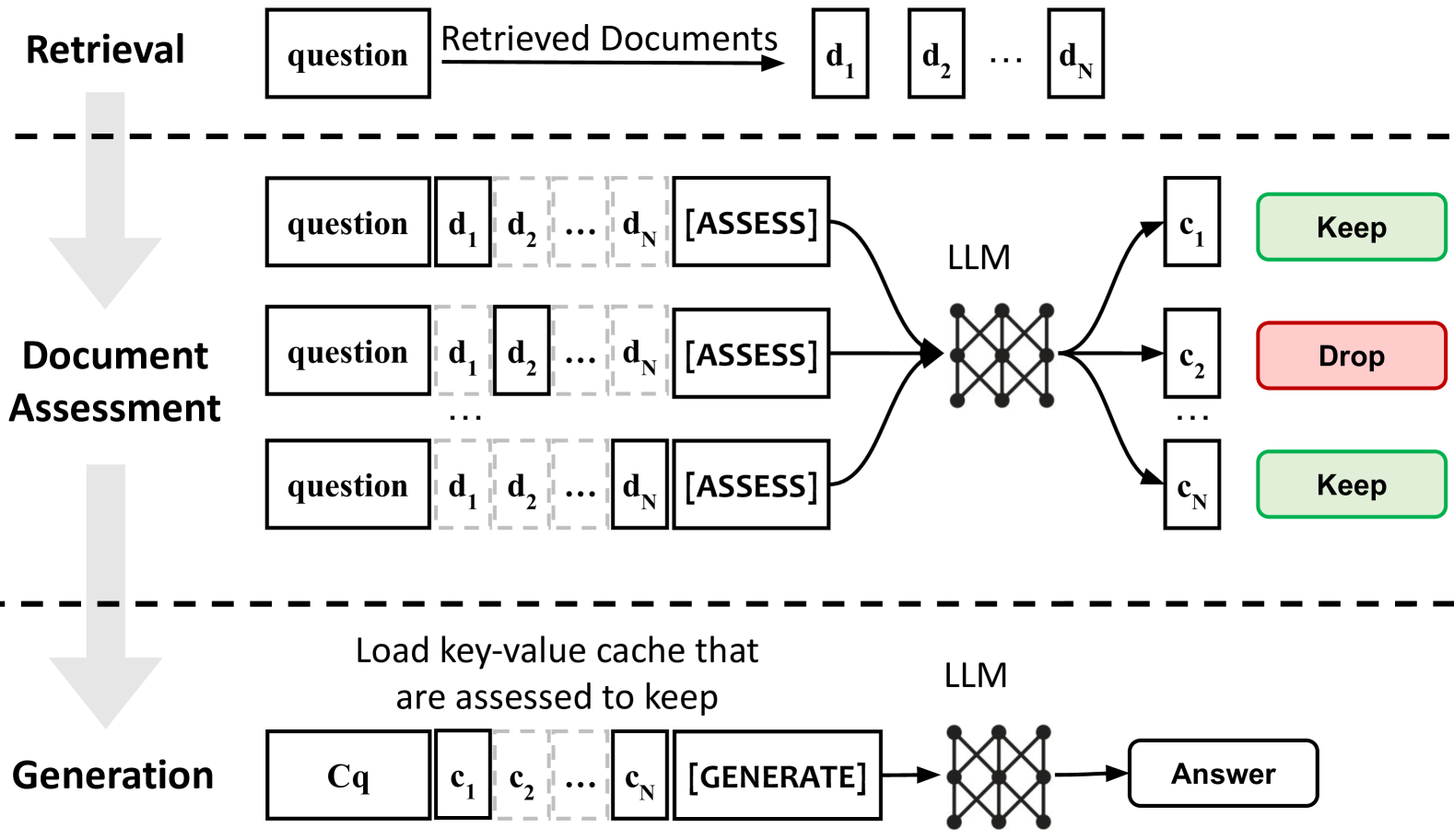
Overview of the Sparse RAG inference process, comparing dense retrieval attention with the proposed sparse mechanism.
Evaluation Highlights
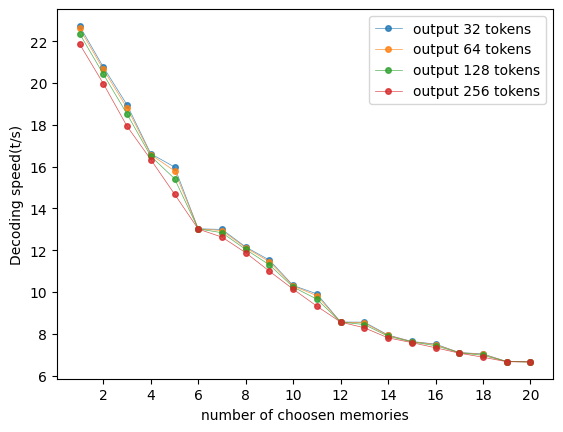
- Achieves 2x to 3x faster decoding speed compared to standard Dense RAG and PCW-RAG on mobile devices (Samsung S21 Ultra)
- Maintains or improves generation quality (e.g., +1.89% F1 on PopQA, +2.67% F1 on AmbigQA vs baselines) by effectively filtering noise
- Outperforms Corrective-RAG (CRAG) using an efficient 'in-place' classifier rather than an external T5 model
Breakthrough Assessment
7/10
A strong practical engineering contribution that solves the specific bottleneck of RAG latency on decoder-only models without sacrificing quality. It effectively combines parallel encoding with dynamic sparsity.