📝 Paper Summary
Agentic RAG pipeline
Process Supervision
DecEx-RAG models retrieval-augmented generation as a Markov Decision Process that decouples decision-making from execution, using a pruning strategy to efficiently construct process-supervision data for training.
Core Problem
Current outcome-supervised RL methods for Agentic RAG suffer from inefficient exploration, sparse rewards, and ambiguous feedback that fails to optimize intermediate steps like sub-question generation or retrieval decisions.
Why it matters:
- Sparse reward signals in outcome-based RL require excessive data and training steps to converge
- Global rewards (final answer correctness) cannot distinguish which specific step (retrieval vs. reasoning) caused a failure
- Inefficient exploration in search trees leads to exponential computational costs when generating training data for multi-step reasoning
Concrete Example:
In Search-R1, a model might correctly retrieve information about a director's nationality but still output the wrong answer 'No' due to reward hacking, where the reasoning process contradicts the conclusion. DecEx-RAG ensures the reasoning path aligns with the final answer.
Key Novelty
Decoupled Decision and Execution MDP with Pruning (DecEx-RAG)
- Models RAG as an MDP with two distinct stages: 'Decision' (whether to stop or retrieve) and 'Execution' (generating the actual sub-question or query), allowing fine-grained optimization of both efficiency and quality
- Introduces a 'Pruning Search' strategy during data generation that simulates outcomes (rollouts) for intermediate steps, pruning redundant branches to keep data expansion linear rather than exponential
Architecture
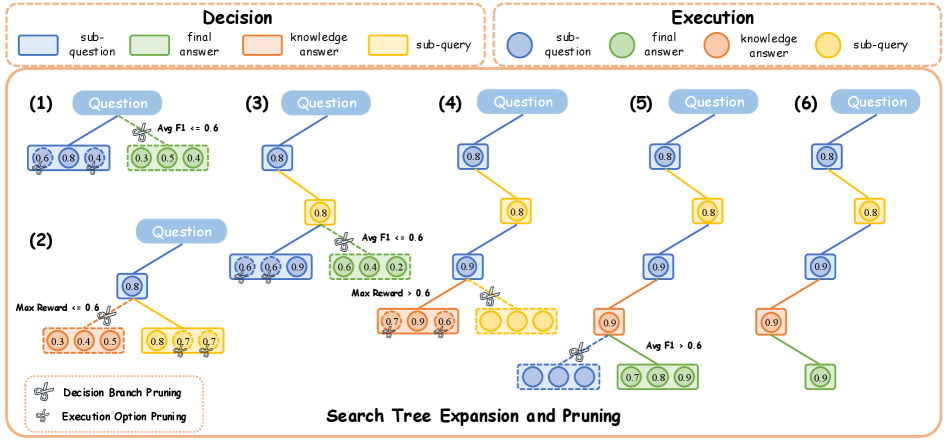
The DecEx-RAG framework showing the MDP process of search tree expansion, pruning, and training data construction.
Evaluation Highlights
- +6.3% average improvement over the outcome-supervised baseline Search-R1 across six QA datasets
- Pruning strategy speeds up data construction by ~6x compared to no-pruning expansion while maintaining equivalent model performance
- Outperforms Search-R1 by +8.6% on HotpotQA and +11.8% on 2WikiMultiHopQA (F1 score)
Breakthrough Assessment
8/10
Significant data efficiency gains (6x speedup) and consistent performance improvements over strong RL baselines like Search-R1. The explicit decoupling of decision and execution in MDP offers a cleaner framework for Agentic RAG.